 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrent Credit Assignment for Data-efficient Reinforcement Learning
Paper and Code
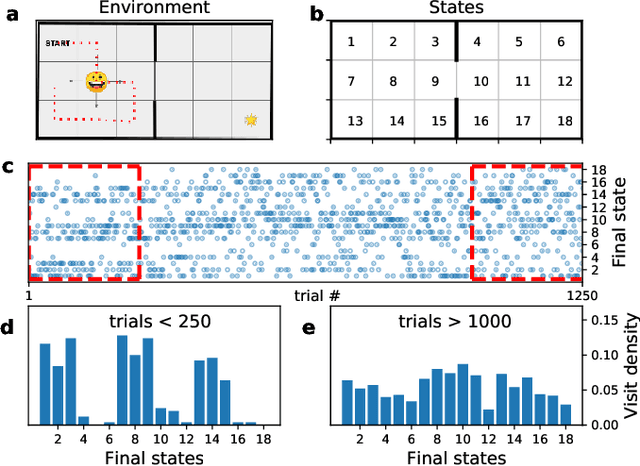
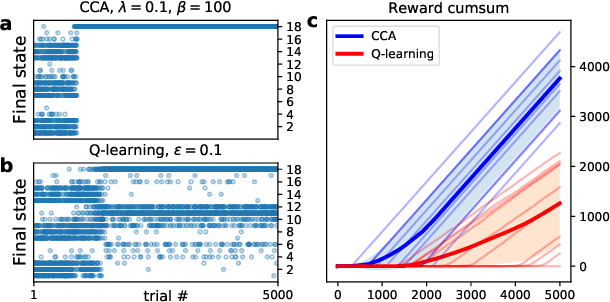
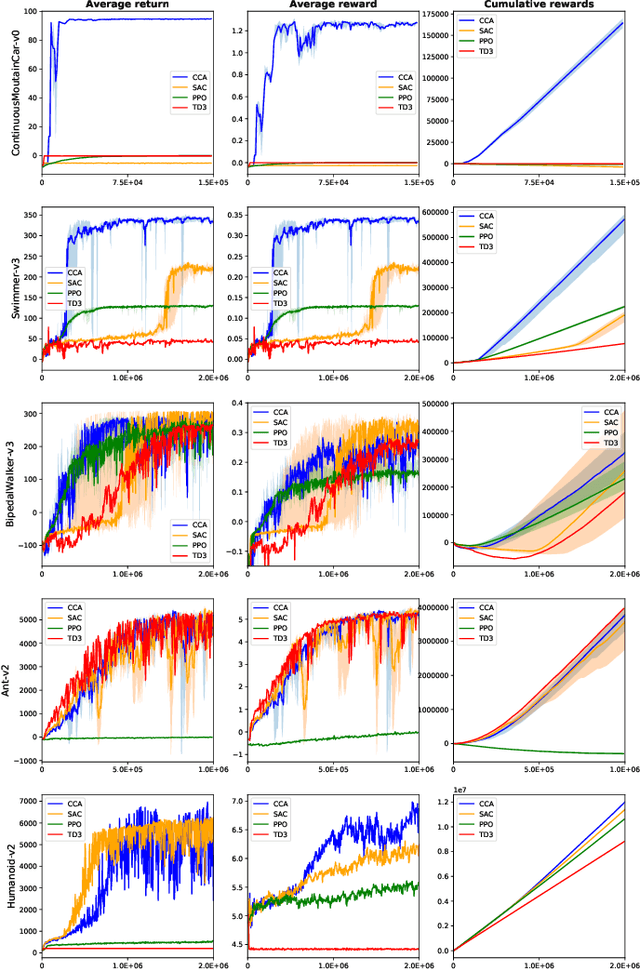
The capability to widely sample the state and action spaces is a key ingredient toward building effective reinforcement learning algorithms. The variational optimization principles exposed in this paper emphasize the importance of an occupancy model to synthesizes the general distribution of the agent's environmental states over which it can act (defining a virtual ``territory''). The occupancy model is the subject of frequent updates as the exploration progresses and that new states are undisclosed during the course of the training. By making a uniform prior assumption, the resulting objective expresses a balance between two concurrent tendencies, namely the widening of the occupancy space and the maximization of the rewards, reminding of the classical exploration/exploitation trade-off. Implemented on an actor-critic off-policy on classic continuous action benchmarks, it is shown to provide significant increase in the sampling efficacy, that is reflected in a reduced training time and higher returns, in both the dense and the sparse rewards cases.