 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task, Multi-Modal Approach for Predicting Categorical and Dimensional Emotions
Dec 31, 2023



Speech emotion recognition (SER) has received a great deal of attention in recent years in the context of spontaneous conversations. While there have been notable results on datasets like the well known corpus of naturalistic dyadic conversations, IEMOCAP, for both the case of categorical and dimensional emotions, there are few papers which try to predict both paradigms at the same time. Therefore, in this work, we aim to highlight the performance contribution of multi-task learning by proposing a multi-task, multi-modal system that predicts categorical and dimensional emotions. The results emphasise the importance of cross-regularisation between the two types of emotions. Our approach consists of a multi-task, multi-modal architecture that uses parallel feature refinement through self-attention for the feature of each modality. In order to fuse the features, our model introduces a set of learnable bridge tokens that merge the acoustic and linguistic features with the help of cross-attention. Our experiments for categorical emotions on 10-fold validation yield results comparable to the current state-of-the-art. In our configuration, our multi-task approach provides better results compared to learning each paradigm separately. On top of that, our best performing model achieves a high result for valence compared to the previous multi-task experiments.
End-to-End Continuous Speech Emotion Recognition in Real-life Customer Service Call Center Conversations
Oct 02, 2023Speech Emotion recognition (SER) in call center conversations has emerged as a valuable tool for assessing the quality of interactions between clients and agents. In contrast to controlled laboratory environments, real-life conversations take place under uncontrolled conditions and are subject to contextual factors that influence the expression of emotions. In this paper, we present our approach to constructing a large-scale reallife dataset (CusEmo) for continuous SER in customer service call center conversations. We adopted the dimensional emotion annotation approach to capture the subtlety, complexity, and continuity of emotions in real-life call center conversations, while annotating contextual information. The study also addresses the challenges encountered during the application of the End-to-End (E2E) SER system to the dataset, including determining the appropriate label sampling rate and input segment length, as well as integrating contextual information (interlocutor's gender and empathy level) with different weights using multitask learning. The result shows that incorporating the empathy level information improved the model's performance.
Multiscale Contextual Learning for Speech Emotion Recognition in Emergency Call Center Conversations
Aug 28, 2023



Emotion recognition in conversations is essential for ensuring advanced human-machine interactions. However, creating robust and accurate emotion recognition systems in real life is challenging, mainly due to the scarcity of emotion datasets collected in the wild and the inability to take into account the dialogue context. The CEMO dataset, composed of conversations between agents and patients during emergency calls to a French call center, fills this gap. The nature of these interactions highlights the role of the emotional flow of the conversation in predicting patient emotions, as context can often make a difference in understanding actual feelings. This paper presents a multi-scale conversational context learning approach for speech emotion recognition, which takes advantage of this hypothesis. We investigated this approach on both speech transcriptions and acoustic segments. Experimentally, our method uses the previous or next information of the targeted segment. In the text domain, we tested the context window using a wide range of tokens (from 10 to 100) and at the speech turns level, considering inputs from both the same and opposing speakers. According to our tests, the context derived from previous tokens has a more significant influence on accurate prediction than the following tokens. Furthermore, taking the last speech turn of the same speaker in the conversation seems useful. In the acoustic domain, we conducted an in-depth analysis of the impact of the surrounding emotions on the prediction. While multi-scale conversational context learning using Transformers can enhance performance in the textual modality for emergency call recordings, incorporating acoustic context is more challenging.
Exploring Attention Mechanisms for Multimodal Emotion Recognition in an Emergency Call Center Corpus
Jun 12, 2023



The emotion detection technology to enhance human decision-making is an important research issue for real-world applications, but real-life emotion datasets are relatively rare and small. The experiments conducted in this paper use the CEMO, which was collected in a French emergency call center. Two pre-trained models based on speech and text were fine-tuned for speech emotion recognition. Using pre-trained Transformer encoders mitigates our data's limited and sparse nature. This paper explores the different fusion strategies of these modality-specific models. In particular, fusions with and without cross-attention mechanisms were tested to gather the most relevant information from both the speech and text encoders. We show that multimodal fusion brings an absolute gain of 4-9% with respect to either single modality and that the Symmetric multi-headed cross-attention mechanism performed better than late classical fusion approaches. Our experiments also suggest that for the real-life CEMO corpus, the audio component encodes more emotive information than the textual one.
* 5 pages, 2 figures, 4 tables
End-to-End Speech Emotion Recognition: Challenges of Real-Life Emergency Call Centers Data Recordings
Oct 28, 2021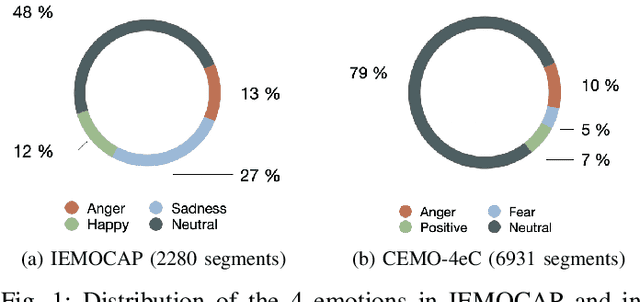
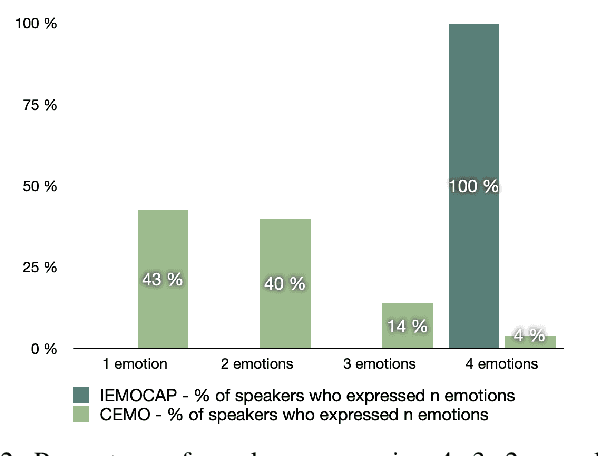
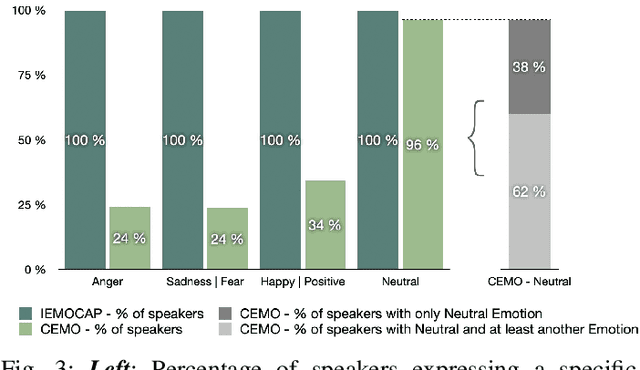
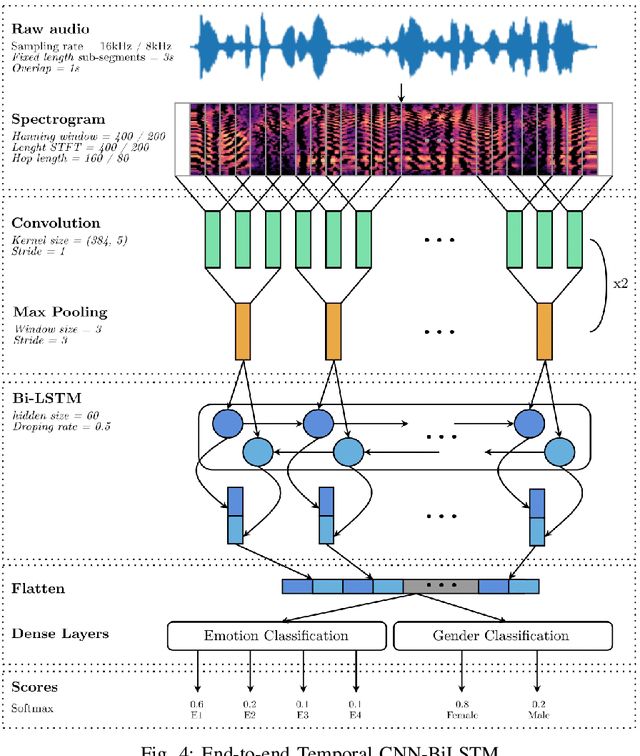
Recognizing a speaker's emotion from their speech can be a key element in emergency call centers. End-to-end deep learning systems for speech emotion recognition now achieve equivalent or even better results than conventional machine learning approaches. In this paper, in order to validate the performance of our neural network architecture for emotion recognition from speech, we first trained and tested it on the widely used corpus accessible by the community, IEMOCAP. We then used the same architecture as the real life corpus, CEMO, composed of 440 dialogs (2h16m) from 485 speakers. The most frequent emotions expressed by callers in these real life emergency dialogues are fear, anger and positive emotions such as relief. In the IEMOCAP general topic conversations, the most frequent emotions are sadness, anger and happiness. Using the same end-to-end deep learning architecture, an Unweighted Accuracy Recall (UA) of 63% is obtained on IEMOCAP and a UA of 45.6% on CEMO, each with 4 classes. Using only 2 classes (Anger, Neutral), the results for CEMO are 76.9% UA compared to 81.1% UA for IEMOCAP. We expect that these encouraging results with CEMO can be improved by combining the audio channel with the linguistic channel. Real-life emotions are clearly more complex than acted ones, mainly due to the large diversity of emotional expressions of speakers. Index Terms-emotion detection, end-to-end deep learning architecture, call center, real-life database, complex emotions.
CNN+LSTM Architecture for Speech Emotion Recognition with Data Augmentation
Sep 11, 2018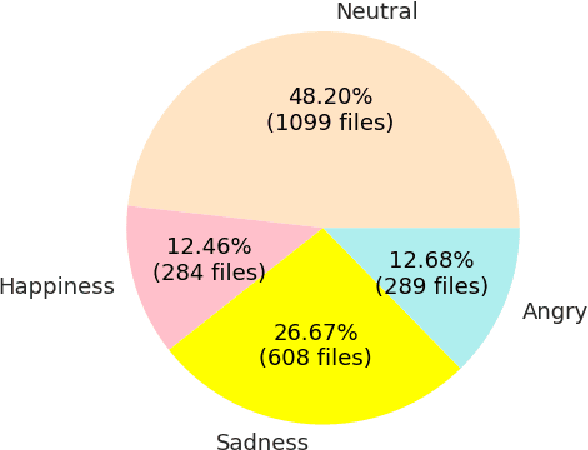

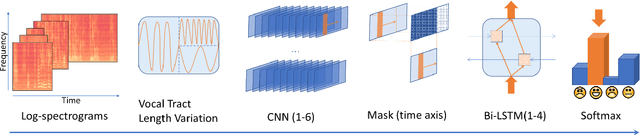
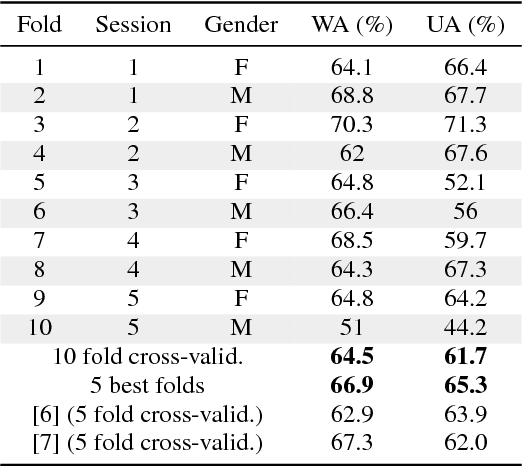
In this work we design a neural network for recognizing emotions in speech, using the IEMOCAP dataset. Following the latest advances in audio analysis, we use an architecture involving both convolutional layers, for extracting high-level features from raw spectrograms, and recurrent ones for aggregating long-term dependencies. We examine the techniques of data augmentation with vocal track length perturbation, layer-wise optimizer adjustment, batch normalization of recurrent layers and obtain highly competitive results of 64.5% for weighted accuracy and 61.7% for unweighted accuracy on four emotions.
* 5 pages, 3 figures