 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Emotion Recognition: Challenges of Real-Life Emergency Call Centers Data Recordings
Paper and Code
Oct 28, 2021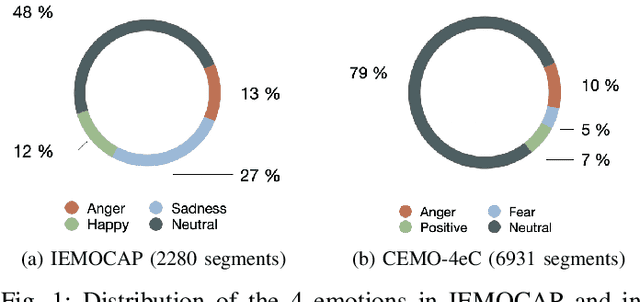
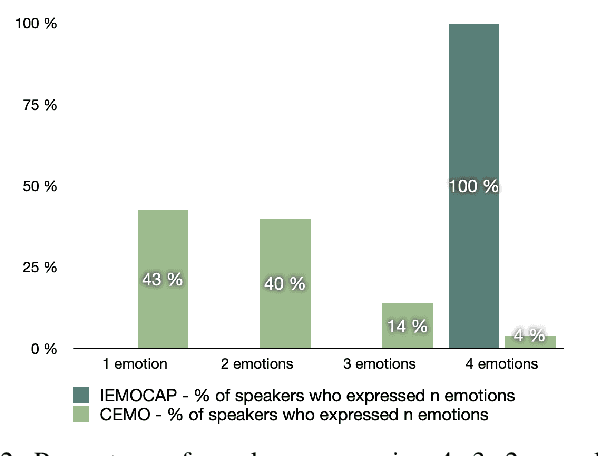
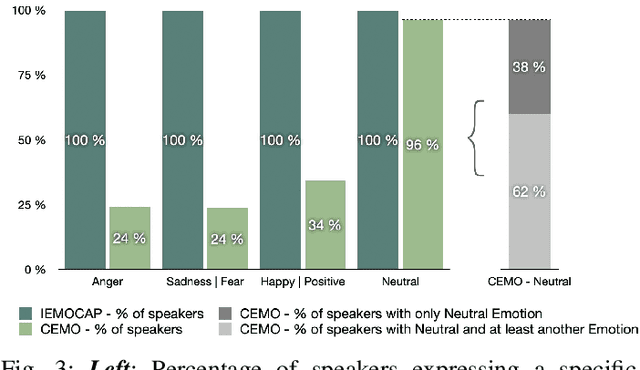
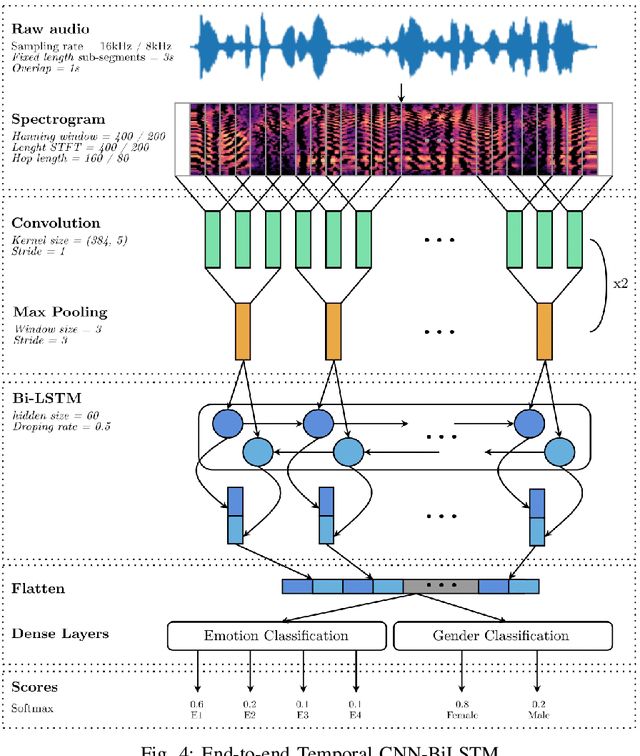
Recognizing a speaker's emotion from their speech can be a key element in emergency call centers. End-to-end deep learning systems for speech emotion recognition now achieve equivalent or even better results than conventional machine learning approaches. In this paper, in order to validate the performance of our neural network architecture for emotion recognition from speech, we first trained and tested it on the widely used corpus accessible by the community, IEMOCAP. We then used the same architecture as the real life corpus, CEMO, composed of 440 dialogs (2h16m) from 485 speakers. The most frequent emotions expressed by callers in these real life emergency dialogues are fear, anger and positive emotions such as relief. In the IEMOCAP general topic conversations, the most frequent emotions are sadness, anger and happiness. Using the same end-to-end deep learning architecture, an Unweighted Accuracy Recall (UA) of 63% is obtained on IEMOCAP and a UA of 45.6% on CEMO, each with 4 classes. Using only 2 classes (Anger, Neutral), the results for CEMO are 76.9% UA compared to 81.1% UA for IEMOCAP. We expect that these encouraging results with CEMO can be improved by combining the audio channel with the linguistic channel. Real-life emotions are clearly more complex than acted ones, mainly due to the large diversity of emotional expressions of speakers. Index Terms-emotion detection, end-to-end deep learning architecture, call center, real-life database, complex emotions.