Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN+LSTM Architecture for Speech Emotion Recognition with Data Augmentation
Sep 11, 2018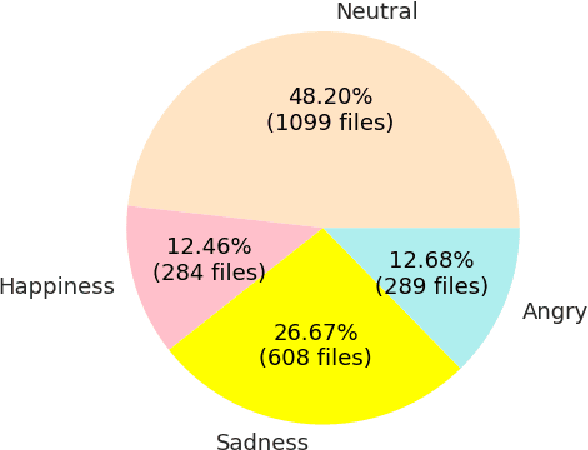

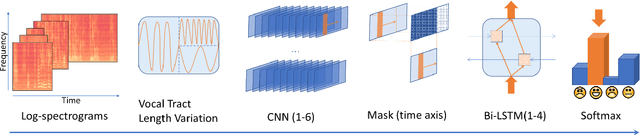
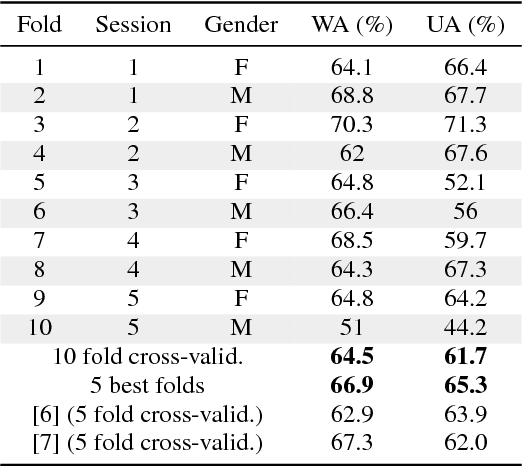
In this work we design a neural network for recognizing emotions in speech, using the IEMOCAP dataset. Following the latest advances in audio analysis, we use an architecture involving both convolutional layers, for extracting high-level features from raw spectrograms, and recurrent ones for aggregating long-term dependencies. We examine the techniques of data augmentation with vocal track length perturbation, layer-wise optimizer adjustment, batch normalization of recurrent layers and obtain highly competitive results of 64.5% for weighted accuracy and 61.7% for unweighted accuracy on four emotions.
* Workshop on Speech, Music and Mind 2018
* 5 pages, 3 figures
* 5 pages, 3 figures
Via