 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARUQULA -- An LLM based Text2SPARQL Approach using ReAct and Knowledge Graph Exploration Utilities
Oct 02, 2025Interacting with knowledge graphs can be a daunting task for people without a background in computer science since the query language that is used (SPARQL) has a high barrier of entry. Large language models (LLMs) can lower that barrier by providing support in the form of Text2SPARQL translation. In this paper we introduce a generalized method based on SPINACH, an LLM backed agent that translates natural language questions to SPARQL queries not in a single shot, but as an iterative process of exploration and execution. We describe the overall architecture and reasoning behind our design decisions, and also conduct a thorough analysis of the agent behavior to gain insights into future areas for targeted improvements. This work was motivated by the Text2SPARQL challenge, a challenge that was held to facilitate improvements in the Text2SPARQL domain.
How do Scaling Laws Apply to Knowledge Graph Engineering Tasks? The Impact of Model Size on Large Language Model Performance
May 22, 2025When using Large Language Models (LLMs) to support Knowledge Graph Engineering (KGE), one of the first indications when searching for an appropriate model is its size. According to the scaling laws, larger models typically show higher capabilities. However, in practice, resource costs are also an important factor and thus it makes sense to consider the ratio between model performance and costs. The LLM-KG-Bench framework enables the comparison of LLMs in the context of KGE tasks and assesses their capabilities of understanding and producing KGs and KG queries. Based on a dataset created in an LLM-KG-Bench run covering 26 open state-of-the-art LLMs, we explore the model size scaling laws specific to KGE tasks. In our analyses, we assess how benchmark scores evolve between different model size categories. Additionally, we inspect how the general score development of single models and families of models correlates to their size. Our analyses revealed that, with a few exceptions, the model size scaling laws generally also apply to the selected KGE tasks. However, in some cases, plateau or ceiling effects occurred, i.e., the task performance did not change much between a model and the next larger model. In these cases, smaller models could be considered to achieve high cost-effectiveness. Regarding models of the same family, sometimes larger models performed worse than smaller models of the same family. These effects occurred only locally. Hence it is advisable to additionally test the next smallest and largest model of the same family.
LLM-KG-Bench 3.0: A Compass for SemanticTechnology Capabilities in the Ocean of LLMs
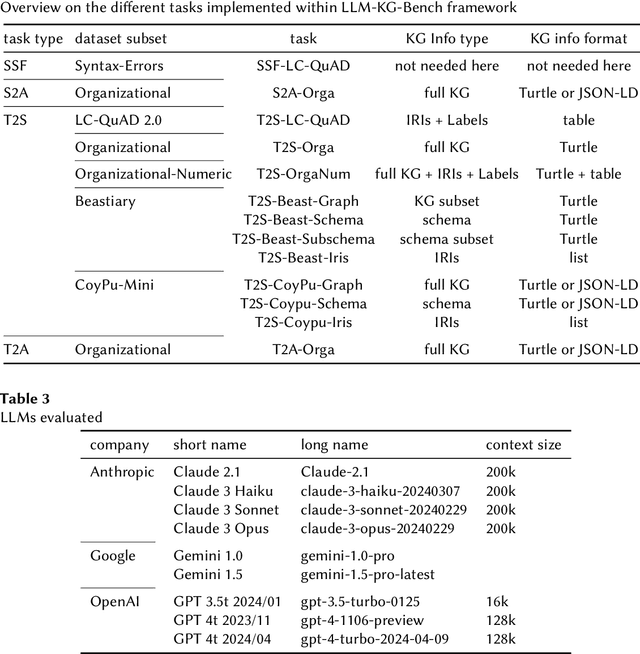
May 19, 2025Current Large Language Models (LLMs) can assist developing program code beside many other things, but can they support working with Knowledge Graphs (KGs) as well? Which LLM is offering the best capabilities in the field of Semantic Web and Knowledge Graph Engineering (KGE)? Is this possible to determine without checking many answers manually? The LLM-KG-Bench framework in Version 3.0 is designed to answer these questions. It consists of an extensible set of tasks for automated evaluation of LLM answers and covers different aspects of working with semantic technologies. In this paper the LLM-KG-Bench framework is presented in Version 3 along with a dataset of prompts, answers and evaluations generated with it and several state-of-the-art LLMs. Significant enhancements have been made to the framework since its initial release, including an updated task API that offers greater flexibility in handling evaluation tasks, revised tasks, and extended support for various open models through the vllm library, among other improvements. A comprehensive dataset has been generated using more than 30 contemporary open and proprietary LLMs, enabling the creation of exemplary model cards that demonstrate the models' capabilities in working with RDF and SPARQL, as well as comparing their performance on Turtle and JSON-LD RDF serialization tasks.
Assessing SPARQL capabilities of Large Language Models
Sep 09, 2024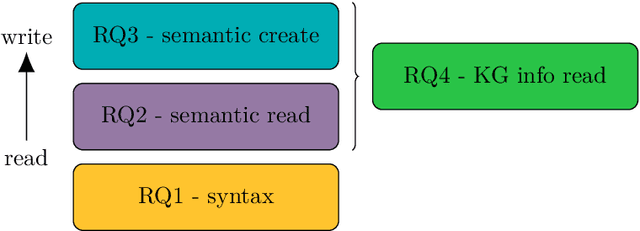

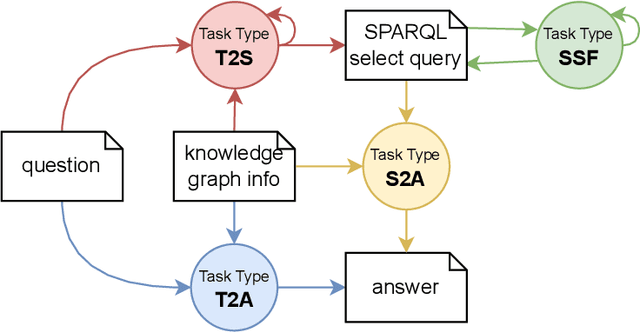
The integration of Large Language Models (LLMs) with Knowledge Graphs (KGs) offers significant synergistic potential for knowledge-driven applications. One possible integration is the interpretation and generation of formal languages, such as those used in the Semantic Web, with SPARQL being a core technology for accessing KGs. In this paper, we focus on measuring out-of-the box capabilities of LLMs to work with SPARQL and more specifically with SPARQL SELECT queries applying a quantitative approach. We implemented various benchmarking tasks in the LLM-KG-Bench framework for automated execution and evaluation with several LLMs. The tasks assess capabilities along the dimensions of syntax, semantic read, semantic create, and the role of knowledge graph prompt inclusion. With this new benchmarking tasks, we evaluated a selection of GPT, Gemini, and Claude models. Our findings indicate that working with SPARQL SELECT queries is still challenging for LLMs and heavily depends on the specific LLM as well as the complexity of the task. While fixing basic syntax errors seems to pose no problems for the best of the current LLMs evaluated, creating semantically correct SPARQL SELECT queries is difficult in several cases.
Leveraging small language models for Text2SPARQL tasks to improve the resilience of AI assistance
May 27, 2024



In this work we will show that language models with less than one billion parameters can be used to translate natural language to SPARQL queries after fine-tuning. Using three different datasets ranging from academic to real world, we identify prerequisites that the training data must fulfill in order for the training to be successful. The goal is to empower users of semantic web technology to use AI assistance with affordable commodity hardware, making them more resilient against external factors.
Benchmarking the Abilities of Large Language Models for RDF Knowledge Graph Creation and Comprehension: How Well Do LLMs Speak Turtle?
Sep 29, 2023

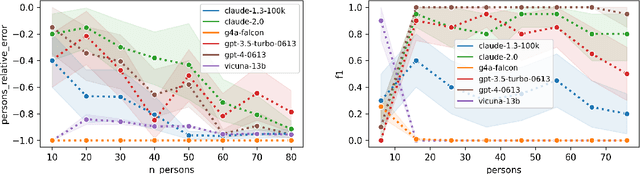
Large Language Models (LLMs) are advancing at a rapid pace, with significant improvements at natural language processing and coding tasks. Yet, their ability to work with formal languages representing data, specifically within the realm of knowledge graph engineering, remains under-investigated. To evaluate the proficiency of various LLMs, we created a set of five tasks that probe their ability to parse, understand, analyze, and create knowledge graphs serialized in Turtle syntax. These tasks, each embodying distinct degrees of complexity and being able to scale with the size of the problem, have been integrated into our automated evaluation system, the LLM-KG-Bench. The evaluation encompassed four commercially available LLMs - GPT-3.5, GPT-4, Claude 1.3, and Claude 2.0, as well as two freely accessible offline models, GPT4All Vicuna and GPT4All Falcon 13B. This analysis offers an in-depth understanding of the strengths and shortcomings of LLMs in relation to their application within RDF knowledge graph engineering workflows utilizing Turtle representation. While our findings show that the latest commercial models outperform their forerunners in terms of proficiency with the Turtle language, they also reveal an apparent weakness. These models fall short when it comes to adhering strictly to the output formatting constraints, a crucial requirement in this context.
Developing a Scalable Benchmark for Assessing Large Language Models in Knowledge Graph Engineering
Aug 31, 2023


As the field of Large Language Models (LLMs) evolves at an accelerated pace, the critical need to assess and monitor their performance emerges. We introduce a benchmarking framework focused on knowledge graph engineering (KGE) accompanied by three challenges addressing syntax and error correction, facts extraction and dataset generation. We show that while being a useful tool, LLMs are yet unfit to assist in knowledge graph generation with zero-shot prompting. Consequently, our LLM-KG-Bench framework provides automatic evaluation and storage of LLM responses as well as statistical data and visualization tools to support tracking of prompt engineering and model performance.
LLM-assisted Knowledge Graph Engineering: Experiments with ChatGPT
Jul 13, 2023Knowledge Graphs (KG) provide us with a structured, flexible, transparent, cross-system, and collaborative way of organizing our knowledge and data across various domains in society and industrial as well as scientific disciplines. KGs surpass any other form of representation in terms of effectiveness. However, Knowledge Graph Engineering (KGE) requires in-depth experiences of graph structures, web technologies, existing models and vocabularies, rule sets, logic, as well as best practices. It also demands a significant amount of work. Considering the advancements in large language models (LLMs) and their interfaces and applications in recent years, we have conducted comprehensive experiments with ChatGPT to explore its potential in supporting KGE. In this paper, we present a selection of these experiments and their results to demonstrate how ChatGPT can assist us in the development and management of KGs.