 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARUQULA -- An LLM based Text2SPARQL Approach using ReAct and Knowledge Graph Exploration Utilities
Oct 02, 2025Interacting with knowledge graphs can be a daunting task for people without a background in computer science since the query language that is used (SPARQL) has a high barrier of entry. Large language models (LLMs) can lower that barrier by providing support in the form of Text2SPARQL translation. In this paper we introduce a generalized method based on SPINACH, an LLM backed agent that translates natural language questions to SPARQL queries not in a single shot, but as an iterative process of exploration and execution. We describe the overall architecture and reasoning behind our design decisions, and also conduct a thorough analysis of the agent behavior to gain insights into future areas for targeted improvements. This work was motivated by the Text2SPARQL challenge, a challenge that was held to facilitate improvements in the Text2SPARQL domain.
LLM-KG-Bench 3.0: A Compass for SemanticTechnology Capabilities in the Ocean of LLMs
May 19, 2025Current Large Language Models (LLMs) can assist developing program code beside many other things, but can they support working with Knowledge Graphs (KGs) as well? Which LLM is offering the best capabilities in the field of Semantic Web and Knowledge Graph Engineering (KGE)? Is this possible to determine without checking many answers manually? The LLM-KG-Bench framework in Version 3.0 is designed to answer these questions. It consists of an extensible set of tasks for automated evaluation of LLM answers and covers different aspects of working with semantic technologies. In this paper the LLM-KG-Bench framework is presented in Version 3 along with a dataset of prompts, answers and evaluations generated with it and several state-of-the-art LLMs. Significant enhancements have been made to the framework since its initial release, including an updated task API that offers greater flexibility in handling evaluation tasks, revised tasks, and extended support for various open models through the vllm library, among other improvements. A comprehensive dataset has been generated using more than 30 contemporary open and proprietary LLMs, enabling the creation of exemplary model cards that demonstrate the models' capabilities in working with RDF and SPARQL, as well as comparing their performance on Turtle and JSON-LD RDF serialization tasks.
LLM-assisted Knowledge Graph Engineering: Experiments with ChatGPT
Jul 13, 2023Knowledge Graphs (KG) provide us with a structured, flexible, transparent, cross-system, and collaborative way of organizing our knowledge and data across various domains in society and industrial as well as scientific disciplines. KGs surpass any other form of representation in terms of effectiveness. However, Knowledge Graph Engineering (KGE) requires in-depth experiences of graph structures, web technologies, existing models and vocabularies, rule sets, logic, as well as best practices. It also demands a significant amount of work. Considering the advancements in large language models (LLMs) and their interfaces and applications in recent years, we have conducted comprehensive experiments with ChatGPT to explore its potential in supporting KGE. In this paper, we present a selection of these experiments and their results to demonstrate how ChatGPT can assist us in the development and management of KGs.
Open Data and the Status Quo -- A Fine-Grained Evaluation Framework for Open Data Quality and an Analysis of Open Data portals in Germany
Jun 17, 2021

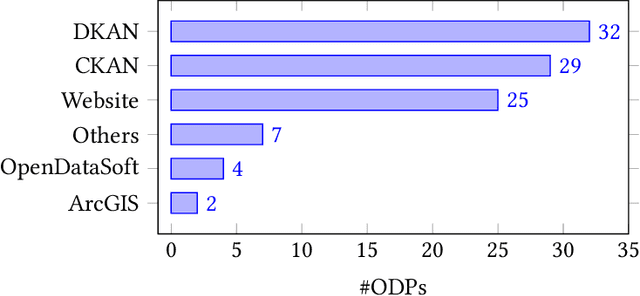

This paper presents a framework for assessing data and metadata quality within Open Data portals. Although a few benchmark frameworks already exist for this purpose, they are not yet detailed enough in both breadth and depth to make valid statements about the actual discoverability and accessibility of publicly available data collections. To address this research gap, we have designed a quality framework that is able to evaluate data quality in Open Data portals on dedicated and fine-grained dimensions, such as interoperability, findability, uniqueness or completeness. Additionally, we propose quality measures that allow for valid assessments regarding cross-portal findability and uniqueness of dataset descriptions. We have validated our novel quality framework for the German Open Data landscape and found out that metadata often still lacks meaningful descriptions and is not yet extensively connected to the Semantic Web.