 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing SPARQL capabilities of Large Language Models
Sep 09, 2024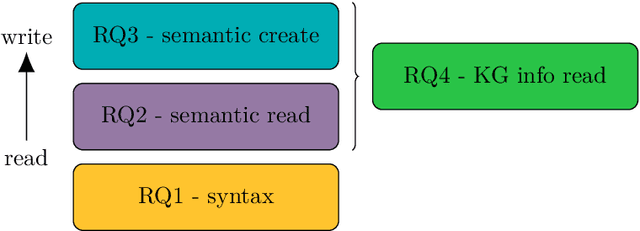

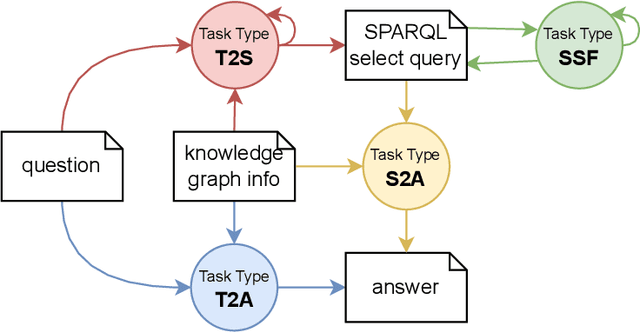
The integration of Large Language Models (LLMs) with Knowledge Graphs (KGs) offers significant synergistic potential for knowledge-driven applications. One possible integration is the interpretation and generation of formal languages, such as those used in the Semantic Web, with SPARQL being a core technology for accessing KGs. In this paper, we focus on measuring out-of-the box capabilities of LLMs to work with SPARQL and more specifically with SPARQL SELECT queries applying a quantitative approach. We implemented various benchmarking tasks in the LLM-KG-Bench framework for automated execution and evaluation with several LLMs. The tasks assess capabilities along the dimensions of syntax, semantic read, semantic create, and the role of knowledge graph prompt inclusion. With this new benchmarking tasks, we evaluated a selection of GPT, Gemini, and Claude models. Our findings indicate that working with SPARQL SELECT queries is still challenging for LLMs and heavily depends on the specific LLM as well as the complexity of the task. While fixing basic syntax errors seems to pose no problems for the best of the current LLMs evaluated, creating semantically correct SPARQL SELECT queries is difficult in several cases.
Benchmarking the Abilities of Large Language Models for RDF Knowledge Graph Creation and Comprehension: How Well Do LLMs Speak Turtle?
Sep 29, 2023

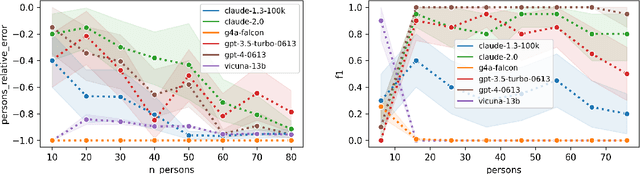
Large Language Models (LLMs) are advancing at a rapid pace, with significant improvements at natural language processing and coding tasks. Yet, their ability to work with formal languages representing data, specifically within the realm of knowledge graph engineering, remains under-investigated. To evaluate the proficiency of various LLMs, we created a set of five tasks that probe their ability to parse, understand, analyze, and create knowledge graphs serialized in Turtle syntax. These tasks, each embodying distinct degrees of complexity and being able to scale with the size of the problem, have been integrated into our automated evaluation system, the LLM-KG-Bench. The evaluation encompassed four commercially available LLMs - GPT-3.5, GPT-4, Claude 1.3, and Claude 2.0, as well as two freely accessible offline models, GPT4All Vicuna and GPT4All Falcon 13B. This analysis offers an in-depth understanding of the strengths and shortcomings of LLMs in relation to their application within RDF knowledge graph engineering workflows utilizing Turtle representation. While our findings show that the latest commercial models outperform their forerunners in terms of proficiency with the Turtle language, they also reveal an apparent weakness. These models fall short when it comes to adhering strictly to the output formatting constraints, a crucial requirement in this context.