 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHit Song Prediction for Pop Music by Siamese CNN with Ranking Loss
Oct 30, 2017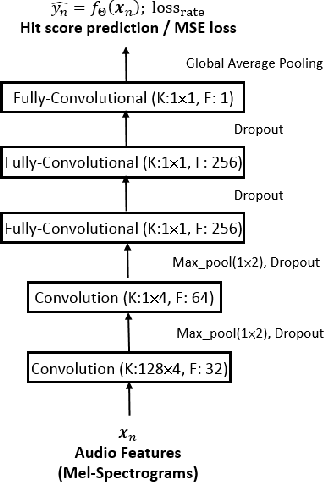
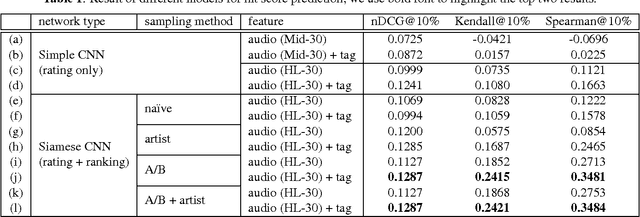
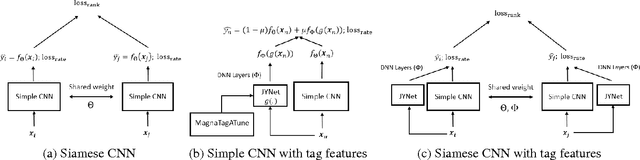
A model for hit song prediction can be used in the pop music industry to identify emerging trends and potential artists or songs before they are marketed to the public. While most previous work formulates hit song prediction as a regression or classification problem, we present in this paper a convolutional neural network (CNN) model that treats it as a ranking problem. Specifically, we use a commercial dataset with daily play-counts to train a multi-objective Siamese CNN model with Euclidean loss and pairwise ranking loss to learn from audio the relative ranking relations among songs. Besides, we devise a number of pair sampling methods according to some empirical observation of the data. Our experiment shows that the proposed model with a sampling method called A/B sampling leads to much higher accuracy in hit song prediction than the baseline regression model. Moreover, we can further improve the accuracy by using a neural attention mechanism to extract the highlights of songs and by using a separate CNN model to offer high-level features of songs.
Abstractive Headline Generation for Spoken Content by Attentive Recurrent Neural Networks with ASR Error Modeling
Dec 26, 2016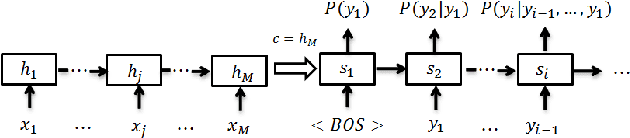
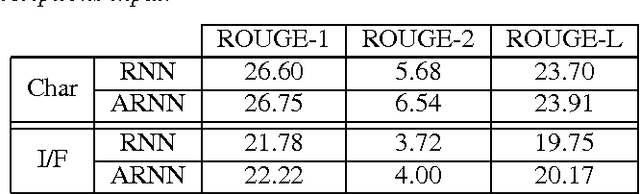
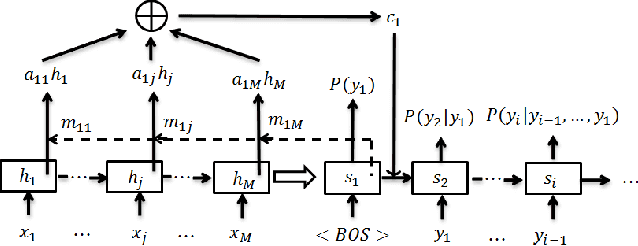
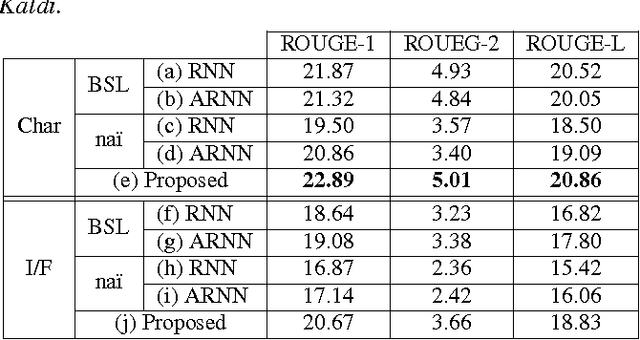
Headline generation for spoken content is important since spoken content is difficult to be shown on the screen and browsed by the user. It is a special type of abstractive summarization, for which the summaries are generated word by word from scratch without using any part of the original content. Many deep learning approaches for headline generation from text document have been proposed recently, all requiring huge quantities of training data, which is difficult for spoken document summarization. In this paper, we propose an ASR error modeling approach to learn the underlying structure of ASR error patterns and incorporate this model in an Attentive Recurrent Neural Network (ARNN) architecture. In this way, the model for abstractive headline generation for spoken content can be learned from abundant text data and the ASR data for some recognizers. Experiments showed very encouraging results and verified that the proposed ASR error model works well even when the input spoken content is recognized by a recognizer very different from the one the model learned from.