 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Global Atlas of Digital Dermatology to Map Innovation and Disparities
Dec 27, 2025The adoption of artificial intelligence in dermatology promises democratized access to healthcare, but model reliability depends on the quality and comprehensiveness of the data fueling these models. Despite rapid growth in publicly available dermatology images, the field lacks quantitative key performance indicators to measure whether new datasets expand clinical coverage or merely replicate what is already known. Here we present SkinMap, a multi-modal framework for the first comprehensive audit of the field's entire data basis. We unify the publicly available dermatology datasets into a single, queryable semantic atlas comprising more than 1.1 million images of skin conditions and quantify (i) informational novelty over time, (ii) dataset redundancy, and (iii) representation gaps across demographics and diagnoses. Despite exponential growth in dataset sizes, informational novelty across time has somewhat plateaued: Some clusters, such as common neoplasms on fair skin, are densely populated, while underrepresented skin types and many rare diseases remain unaddressed. We further identify structural gaps in coverage: Darker skin tones (Fitzpatrick V-VI) constitute only 5.8% of images and pediatric patients only 3.0%, while many rare diseases and phenotype combinations remain sparsely represented. SkinMap provides infrastructure to measure blind spots and steer strategic data acquisition toward undercovered regions of clinical space.
Towards Reliable Dermatology Evaluation Benchmarks
Sep 13, 2023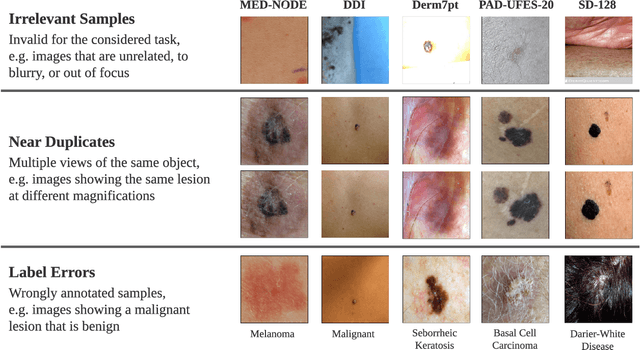
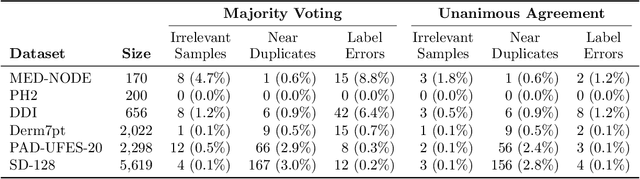
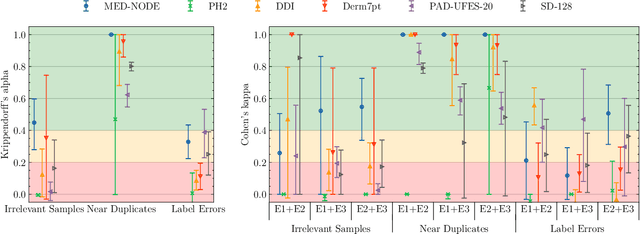
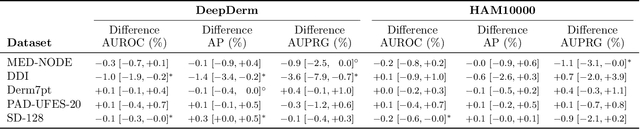
Benchmark datasets for digital dermatology unwittingly contain inaccuracies that reduce trust in model performance estimates. We propose a resource-efficient data cleaning protocol to identify issues that escaped previous curation. The protocol leverages an existing algorithmic cleaning strategy and is followed by a confirmation process terminated by an intuitive stopping criterion. Based on confirmation by multiple dermatologists, we remove irrelevant samples and near duplicates and estimate the percentage of label errors in six dermatology image datasets for model evaluation promoted by the International Skin Imaging Collaboration. Along with this paper, we publish revised file lists for each dataset which should be used for model evaluation. Our work paves the way for more trustworthy performance assessment in digital dermatology.
SelfClean: A Self-Supervised Data Cleaning Strategy
May 26, 2023



Most commonly used benchmark datasets for computer vision contain irrelevant images, near duplicates, and label errors. Consequently, model performance on these benchmarks may not be an accurate estimate of generalization ability. This is a particularly acute concern in computer vision for medicine where datasets are typically small, stakes are high, and annotation processes are expensive and error-prone. In this paper, we propose SelfClean, a general procedure to clean up image datasets exploiting a latent space learned with self-supervision. By relying on self-supervised learning, our approach focuses on intrinsic properties of the data and avoids annotation biases. We formulate dataset cleaning as either a set of ranking problems, where human experts can make decisions with significantly reduced effort, or a set of scoring problems, where decisions can be fully automated based on score distributions. We compare SelfClean against other algorithms on common computer vision benchmarks enhanced with synthetic noise and demonstrate state-of-the-art performance on detecting irrelevant images, near duplicates, and label errors. In addition, we apply our method to multiple image datasets and confirm an improvement in evaluation reliability.