 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer Equipped with Neural Resizer on Facial Expression Recognition Task
Apr 05, 2022

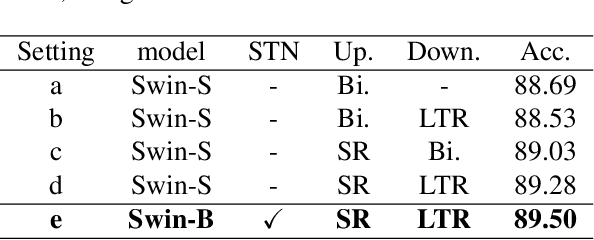

When it comes to wild conditions, Facial Expression Recognition is often challenged with low-quality data and imbalanced, ambiguous labels. This field has much benefited from CNN based approaches; however, CNN models have structural limitation to see the facial regions in distant. As a remedy, Transformer has been introduced to vision fields with global receptive field, but requires adjusting input spatial size to the pretrained models to enjoy their strong inductive bias at hands. We herein raise a question whether using the deterministic interpolation method is enough to feed low-resolution data to Transformer. In this work, we propose a novel training framework, Neural Resizer, to support Transformer by compensating information and downscaling in a data-driven manner trained with loss function balancing the noisiness and imbalance. Experiments show our Neural Resizer with F-PDLS loss function improves the performance with Transformer variants in general and nearly achieves the state-of-the-art performance.
A Vision Based Deep Reinforcement Learning Algorithm for UAV Obstacle Avoidance
Mar 11, 2021
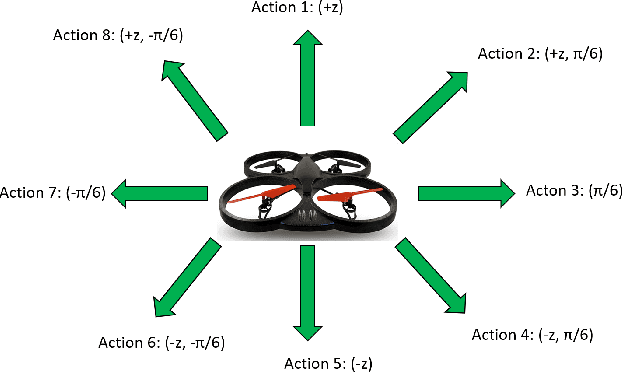


Integration of reinforcement learning with unmanned aerial vehicles (UAVs) to achieve autonomous flight has been an active research area in recent years. An important part focuses on obstacle detection and avoidance for UAVs navigating through an environment. Exploration in an unseen environment can be tackled with Deep Q-Network (DQN). However, value exploration with uniform sampling of actions may lead to redundant states, where often the environments inherently bear sparse rewards. To resolve this, we present two techniques for improving exploration for UAV obstacle avoidance. The first is a convergence-based approach that uses convergence error to iterate through unexplored actions and temporal threshold to balance exploration and exploitation. The second is a guidance-based approach using a Domain Network which uses a Gaussian mixture distribution to compare previously seen states to a predicted next state in order to select the next action. Performance and evaluation of these approaches were implemented in multiple 3-D simulation environments, with variation in complexity. The proposed approach demonstrates a two-fold improvement in average rewards compared to state of the art.