 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Supervised and Unsupervised Segmentation and Classification of Materials Microstructure Images
Feb 10, 2025Microstructure of materials is often characterized through image analysis to understand processing-structure-properties linkages. We propose a largely automated framework that integrates unsupervised and supervised learning methods to classify micrographs according to microstructure phase/class and, for multiphase microstructures, segments them into different homogeneous regions. With the advance of manufacturing and imaging techniques, the ultra-high resolution of imaging that reveals the complexity of microstructures and the rapidly increasing quantity of images (i.e., micrographs) enables and necessitates a more powerful and automated framework to extract materials characteristics and knowledge. The framework we propose can be used to gradually build a database of microstructure classes relevant to a particular process or group of materials, which can help in analyzing and discovering/identifying new materials. The framework has three steps: (1) segmentation of multiphase micrographs through a recently developed score-based method so that different microstructure homogeneous regions can be identified in an unsupervised manner; (2) {identification and classification of} homogeneous regions of micrographs through an uncertainty-aware supervised classification network trained using the segmented micrographs from Step $1$ with their identified labels verified via the built-in uncertainty quantification and minimal human inspection; (3) supervised segmentation (more powerful than the segmentation in Step $1$) of multiphase microstructures through a segmentation network trained with micrographs and the results from Steps $1$-$2$ using a form of data augmentation. This framework can iteratively characterize/segment new homogeneous or multiphase materials while expanding the database to enhance performance. The framework is demonstrated on various sets of materials and texture images.
Concept Drift Monitoring and Diagnostics of Supervised Learning Models via Score Vectors
Dec 12, 2020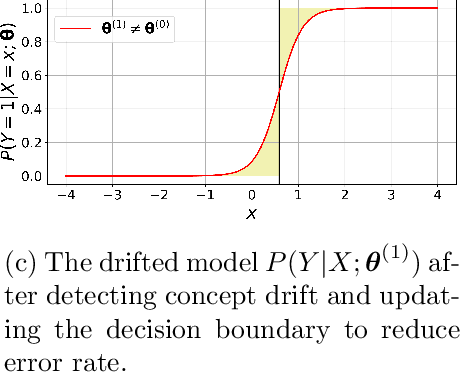
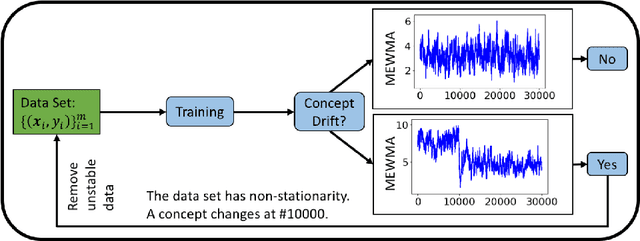
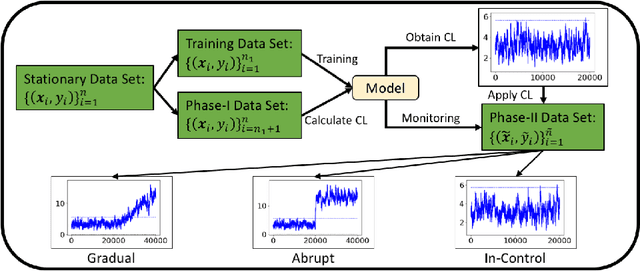
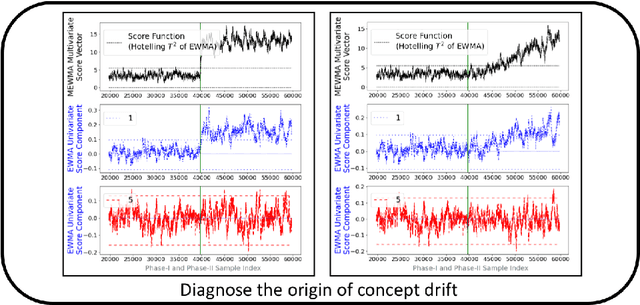
Supervised learning models are one of the most fundamental classes of models. Viewing supervised learning from a probabilistic perspective, the set of training data to which the model is fitted is usually assumed to follow a stationary distribution. However, this stationarity assumption is often violated in a phenomenon called concept drift, which refers to changes over time in the predictive relationship between covariates $\mathbf{X}$ and a response variable $Y$ and can render trained models suboptimal or obsolete. We develop a comprehensive and computationally efficient framework for detecting, monitoring, and diagnosing concept drift. Specifically, we monitor the Fisher score vector, defined as the gradient of the log-likelihood for the fitted model, using a form of multivariate exponentially weighted moving average, which monitors for general changes in the mean of a random vector. In spite of the substantial performance advantages that we demonstrate over popular error-based methods, a score-based approach has not been previously considered for concept drift monitoring. Advantages of the proposed score-based framework include applicability to any parametric model, more powerful detection of changes as shown in theory and experiments, and inherent diagnostic capabilities for helping to identify the nature of the changes.