 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Answer Sets of Disjunctive Answer Set Programs
Jul 15, 2025Answer Set Programming (ASP) provides a powerful declarative paradigm for knowledge representation and reasoning. Recently, counting answer sets has emerged as an important computational problem with applications in probabilistic reasoning, network reliability analysis, and other domains. This has motivated significant research into designing efficient ASP counters. While substantial progress has been made for normal logic programs, the development of practical counters for disjunctive logic programs remains challenging. We present SharpASP-SR, a novel framework for counting answer sets of disjunctive logic programs based on subtractive reduction to projected propositional model counting. Our approach introduces an alternative characterization of answer sets that enables efficient reduction while ensuring that intermediate representations remain of polynomial size. This allows SharpASP-SR to leverage recent advances in projected model counting technology. Through extensive experimental evaluation on diverse benchmarks, we demonstrate that SharpASP-SR significantly outperforms existing counters on instances with large answer set counts. Building on these results, we develop a hybrid counting approach that combines enumeration techniques with SharpASP-SR to achieve state-of-the-art performance across the full spectrum of disjunctive programs.
Probabilistic Explanations for Linear Models
Dec 30, 2024Formal XAI is an emerging field that focuses on providing explanations with mathematical guarantees for the decisions made by machine learning models. A significant amount of work in this area is centered on the computation of "sufficient reasons". Given a model $M$ and an input instance $\vec{x}$, a sufficient reason for the decision $M(\vec{x})$ is a subset $S$ of the features of $\vec{x}$ such that for any instance $\vec{z}$ that has the same values as $\vec{x}$ for every feature in $S$, it holds that $M(\vec{x}) = M(\vec{z})$. Intuitively, this means that the features in $S$ are sufficient to fully justify the classification of $\vec{x}$ by $M$. For sufficient reasons to be useful in practice, they should be as small as possible, and a natural way to reduce the size of sufficient reasons is to consider a probabilistic relaxation; the probability of $M(\vec{x}) = M(\vec{z})$ must be at least some value $\delta \in (0,1]$, for a random instance $\vec{z}$ that coincides with $\vec{x}$ on the features in $S$. Computing small $\delta$-sufficient reasons ($\delta$-SRs) is known to be a theoretically hard problem; even over decision trees--traditionally deemed simple and interpretable models--strong inapproximability results make the efficient computation of small $\delta$-SRs unlikely. We propose the notion of $(\delta, \epsilon)$-SR, a simple relaxation of $\delta$-SRs, and show that this kind of explanation can be computed efficiently over linear models.
Exact ASP Counting with Compact Encodings
Dec 19, 2023


Answer Set Programming (ASP) has emerged as a promising paradigm in knowledge representation and automated reasoning owing to its ability to model hard combinatorial problems from diverse domains in a natural way. Building on advances in propositional SAT solving, the past two decades have witnessed the emergence of well-engineered systems for solving the answer set satisfiability problem, i.e., finding models or answer sets for a given answer set program. In recent years, there has been growing interest in problems beyond satisfiability, such as model counting, in the context of ASP. Akin to the early days of propositional model counting, state-of-the-art exact answer set counters do not scale well beyond small instances. Exact ASP counters struggle with handling larger input formulas. The primary contribution of this paper is a new ASP counting framework, called sharpASP, which counts answer sets avoiding larger input formulas. This relies on an alternative way of defining answer sets that allows for the lifting of key techniques developed in the context of propositional model counting. Our extensive empirical analysis over 1470 benchmarks demonstrates significant performance gain over current state-of-the-art exact answer set counters. Specifically, by using sharpASP, we were able to solve 1062 benchmarks with PAR2 score of 3082 whereas using prior state-of-the-art, we could only solve 895 benchmarks with a PAR2 score of 4205, all other experimental conditions being the same.
Partition Function Estimation: A Quantitative Study
May 24, 2021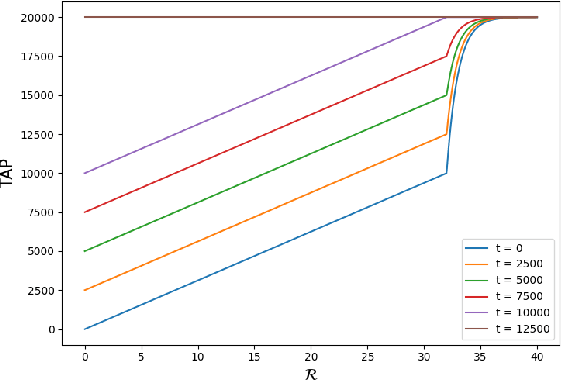
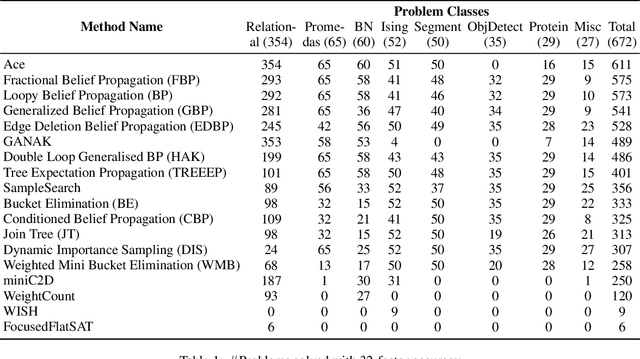
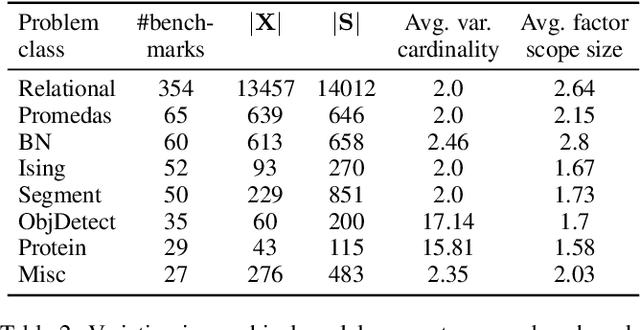

Probabilistic graphical models have emerged as a powerful modeling tool for several real-world scenarios where one needs to reason under uncertainty. A graphical model's partition function is a central quantity of interest, and its computation is key to several probabilistic reasoning tasks. Given the #P-hardness of computing the partition function, several techniques have been proposed over the years with varying guarantees on the quality of estimates and their runtime behavior. This paper seeks to present a survey of 18 techniques and a rigorous empirical study of their behavior across an extensive set of benchmarks. Our empirical study draws up a surprising observation: exact techniques are as efficient as the approximate ones, and therefore, we conclude with an optimistic view of opportunities for the design of approximate techniques with enhanced scalability. Motivated by the observation of an order of magnitude difference between the Virtual Best Solver and the best performing tool, we envision an exciting line of research focused on the development of portfolio solvers.