 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Quantile Networks: Uncertainty-Aware Reinforcement Learning with Applications in Autonomous Driving
May 21, 2021
Reinforcement learning (RL) can be used to create a decision-making agent for autonomous driving. However, previous approaches provide only black-box solutions, which do not offer information on how confident the agent is about its decisions. An estimate of both the aleatoric and epistemic uncertainty of the agent's decisions is fundamental for real-world applications of autonomous driving. Therefore, this paper introduces the Ensemble Quantile Networks (EQN) method, which combines distributional RL with an ensemble approach, to obtain a complete uncertainty estimate. The distribution over returns is estimated by learning its quantile function implicitly, which gives the aleatoric uncertainty, whereas an ensemble of agents is trained on bootstrapped data to provide a Bayesian estimation of the epistemic uncertainty. A criterion for classifying which decisions that have an unacceptable uncertainty is also introduced. The results show that the EQN method can balance risk and time efficiency in different occluded intersection scenarios, by considering the estimated aleatoric uncertainty. Furthermore, it is shown that the trained agent can use the epistemic uncertainty information to identify situations that the agent has not been trained for and thereby avoid making unfounded, potentially dangerous, decisions outside of the training distribution.
Tactical Decision-Making in Autonomous Driving by Reinforcement Learning with Uncertainty Estimation
Apr 22, 2020
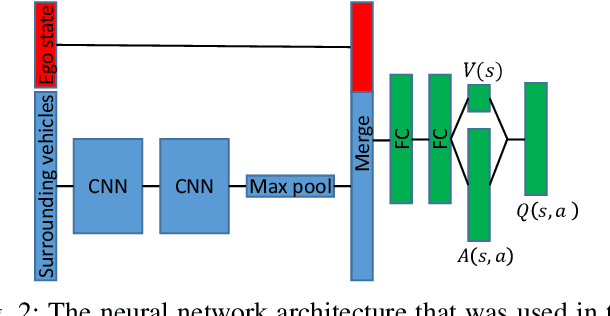
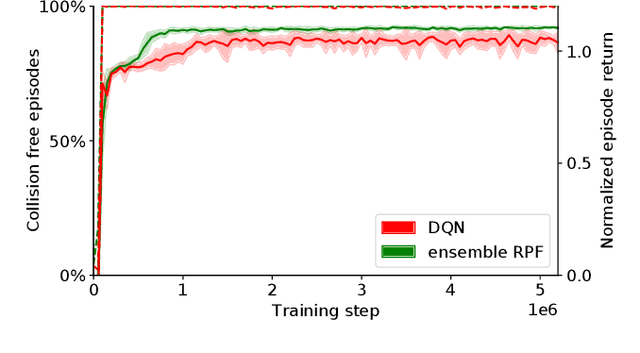
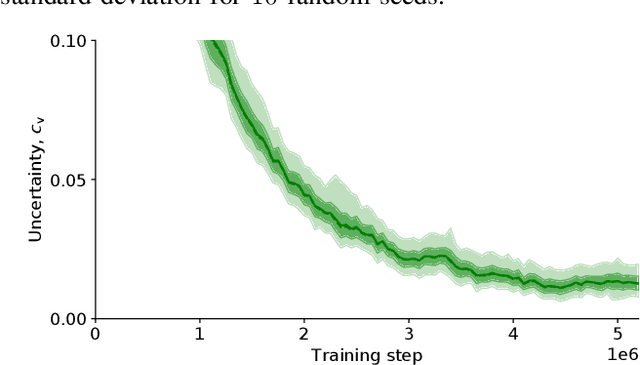
Reinforcement learning (RL) can be used to create a tactical decision-making agent for autonomous driving. However, previous approaches only output decisions and do not provide information about the agent's confidence in the recommended actions. This paper investigates how a Bayesian RL technique, based on an ensemble of neural networks with additional randomized prior functions (RPF), can be used to estimate the uncertainty of decisions in autonomous driving. A method for classifying whether or not an action should be considered safe is also introduced. The performance of the ensemble RPF method is evaluated by training an agent on a highway driving scenario. It is shown that the trained agent can estimate the uncertainty of its decisions and indicate an unacceptable level when the agent faces a situation that is far from the training distribution. Furthermore, within the training distribution, the ensemble RPF agent outperforms a standard Deep Q-Network agent. In this study, the estimated uncertainty is used to choose safe actions in unknown situations. However, the uncertainty information could also be used to identify situations that should be added to the training process.
Combining Planning and Deep Reinforcement Learning in Tactical Decision Making for Autonomous Driving
May 06, 2019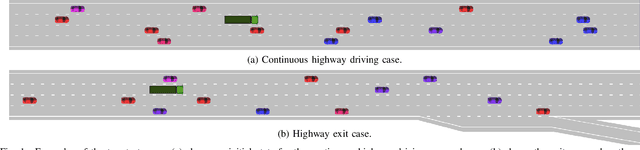
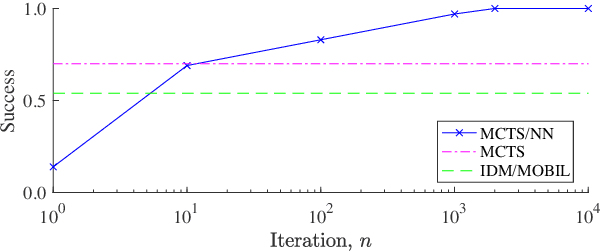

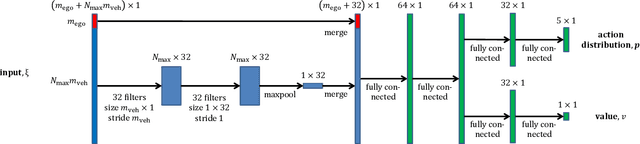
Tactical decision making for autonomous driving is challenging due to the diversity of environments, the uncertainty in the sensor information, and the complex interaction with other road users. This paper introduces a general framework for tactical decision making, which combines the concepts of planning and learning, in the form of Monte Carlo tree search and deep reinforcement learning. The method is based on the AlphaGo Zero algorithm, which is extended to a domain with a continuous state space where self-play cannot be used. The framework is applied to two different highway driving cases in a simulated environment and it is shown to perform better than a commonly used baseline method. The strength of combining planning and learning is also illustrated by a comparison to using the Monte Carlo tree search or the neural network policy separately.
Automated Speed and Lane Change Decision Making using Deep Reinforcement Learning
Nov 01, 2018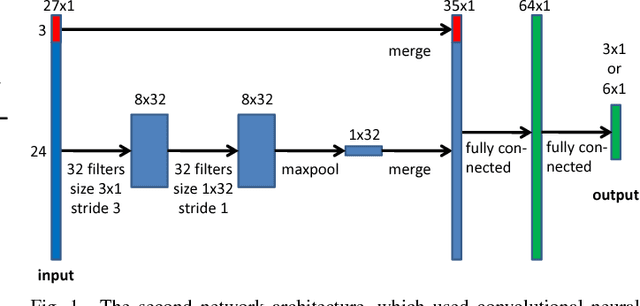
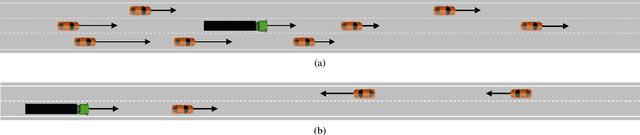
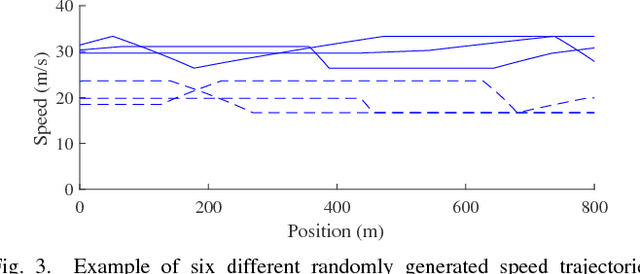
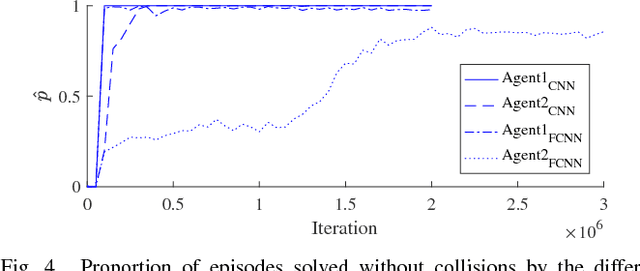
This paper introduces a method, based on deep reinforcement learning, for automatically generating a general purpose decision making function. A Deep Q-Network agent was trained in a simulated environment to handle speed and lane change decisions for a truck-trailer combination. In a highway driving case, it is shown that the method produced an agent that matched or surpassed the performance of a commonly used reference model. To demonstrate the generality of the method, the exact same algorithm was also tested by training it for an overtaking case on a road with oncoming traffic. Furthermore, a novel way of applying a convolutional neural network to high level input that represents interchangeable objects is also introduced.