 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential radial basis function network for sequence modelling
Oct 13, 2020
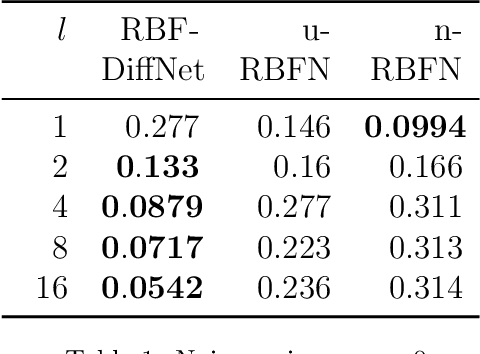


We propose a differential radial basis function (RBF) network termed RBF-DiffNet -- whose hidden layer blocks are partial differential equations (PDEs) linear in terms of the RBF -- to make the baseline RBF network robust to noise in sequential data. Assuming that the sequential data derives from the discretisation of the solution to an underlying PDE, the differential RBF network learns constant linear coefficients of the PDE, consequently regularising the RBF network by following modified backward-Euler updates. We experimentally validate the differential RBF network on the logistic map chaotic timeseries as well as on 30 real-world timeseries provided by Walmart in the M5 forecasting competition. The proposed model is compared with the normalised and unnormalised RBF networks, ARIMA, and ensembles of multilayer perceptrons (MLPs) and recurrent networks with long short-term memory (LSTM) blocks. From the experimental results, RBF-DiffNet consistently shows a marked reduction over the baseline RBF network in terms of the prediction error (e.g., 26% reduction in the root mean squared scaled error on the M5 dataset); RBF-DiffNet also shows a comparable performance to the LSTM ensemble at less than one-sixteenth the LSTM computational time. Our proposed network consequently enables more accurate predictions -- in the presence of observational noise -- in sequence modelling tasks such as timeseries forecasting that leverage the model interpretability, fast training, and function approximation properties of the RBF network.
K-Means Clustering using Tabu Search with Quantized Means
Mar 24, 2017


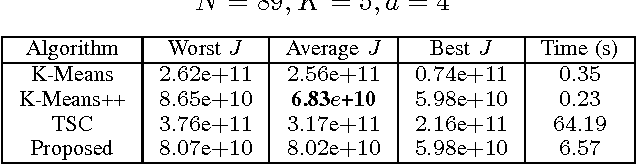
The Tabu Search (TS) metaheuristic has been proposed for K-Means clustering as an alternative to Lloyd's algorithm, which for all its ease of implementation and fast runtime, has the major drawback of being trapped at local optima. While the TS approach can yield superior performance, it involves a high computational complexity. Moreover, the difficulty in parameter selection in the existing TS approach does not make it any more attractive. This paper presents an alternative, low-complexity formulation of the TS optimization procedure for K-Means clustering. This approach does not require many parameter settings. We initially constrain the centers to points in the dataset. We then aim at evolving these centers using a unique neighborhood structure that makes use of gradient information of the objective function. This results in an efficient exploration of the search space, after which the means are refined. The proposed scheme is implemented in MATLAB and tested on four real-world datasets, and it achieves a significant improvement over the existing TS approach in terms of the intra cluster sum of squares and computational time.
Linear classifier design under heteroscedasticity in Linear Discriminant Analysis
Mar 24, 2017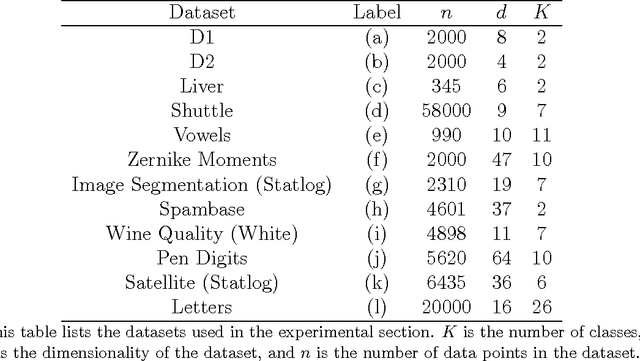



Under normality and homoscedasticity assumptions, Linear Discriminant Analysis (LDA) is known to be optimal in terms of minimising the Bayes error for binary classification. In the heteroscedastic case, LDA is not guaranteed to minimise this error. Assuming heteroscedasticity, we derive a linear classifier, the Gaussian Linear Discriminant (GLD), that directly minimises the Bayes error for binary classification. In addition, we also propose a local neighbourhood search (LNS) algorithm to obtain a more robust classifier if the data is known to have a non-normal distribution. We evaluate the proposed classifiers on two artificial and ten real-world datasets that cut across a wide range of application areas including handwriting recognition, medical diagnosis and remote sensing, and then compare our algorithm against existing LDA approaches and other linear classifiers. The GLD is shown to outperform the original LDA procedure in terms of the classification accuracy under heteroscedasticity. While it compares favourably with other existing heteroscedastic LDA approaches, the GLD requires as much as 60 times lower training time on some datasets. Our comparison with the support vector machine (SVM) also shows that, the GLD, together with the LNS, requires as much as 150 times lower training time to achieve an equivalent classification accuracy on some of the datasets. Thus, our algorithms can provide a cheap and reliable option for classification in a lot of expert systems.