 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Means Clustering using Tabu Search with Quantized Means
Mar 24, 2017


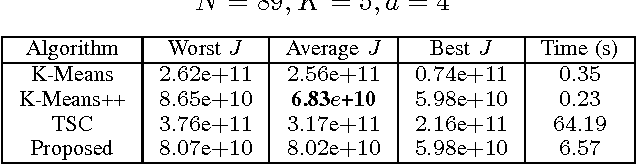
The Tabu Search (TS) metaheuristic has been proposed for K-Means clustering as an alternative to Lloyd's algorithm, which for all its ease of implementation and fast runtime, has the major drawback of being trapped at local optima. While the TS approach can yield superior performance, it involves a high computational complexity. Moreover, the difficulty in parameter selection in the existing TS approach does not make it any more attractive. This paper presents an alternative, low-complexity formulation of the TS optimization procedure for K-Means clustering. This approach does not require many parameter settings. We initially constrain the centers to points in the dataset. We then aim at evolving these centers using a unique neighborhood structure that makes use of gradient information of the objective function. This results in an efficient exploration of the search space, after which the means are refined. The proposed scheme is implemented in MATLAB and tested on four real-world datasets, and it achieves a significant improvement over the existing TS approach in terms of the intra cluster sum of squares and computational time.
Linear classifier design under heteroscedasticity in Linear Discriminant Analysis
Mar 24, 2017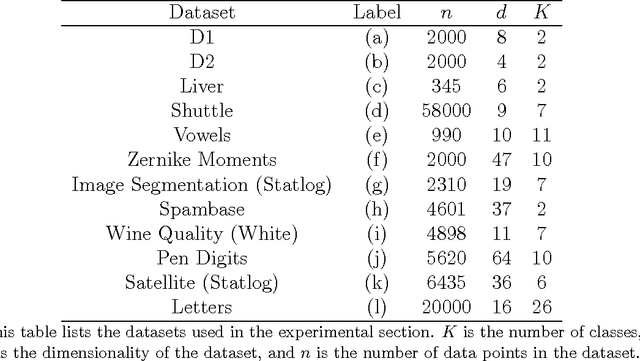



Under normality and homoscedasticity assumptions, Linear Discriminant Analysis (LDA) is known to be optimal in terms of minimising the Bayes error for binary classification. In the heteroscedastic case, LDA is not guaranteed to minimise this error. Assuming heteroscedasticity, we derive a linear classifier, the Gaussian Linear Discriminant (GLD), that directly minimises the Bayes error for binary classification. In addition, we also propose a local neighbourhood search (LNS) algorithm to obtain a more robust classifier if the data is known to have a non-normal distribution. We evaluate the proposed classifiers on two artificial and ten real-world datasets that cut across a wide range of application areas including handwriting recognition, medical diagnosis and remote sensing, and then compare our algorithm against existing LDA approaches and other linear classifiers. The GLD is shown to outperform the original LDA procedure in terms of the classification accuracy under heteroscedasticity. While it compares favourably with other existing heteroscedastic LDA approaches, the GLD requires as much as 60 times lower training time on some datasets. Our comparison with the support vector machine (SVM) also shows that, the GLD, together with the LNS, requires as much as 150 times lower training time to achieve an equivalent classification accuracy on some of the datasets. Thus, our algorithms can provide a cheap and reliable option for classification in a lot of expert systems.