 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Sources and Risk Management Measures in Support of Standards for General-Purpose AI Systems
Oct 30, 2024


There is an urgent need to identify both short and long-term risks from newly emerging types of Artificial Intelligence (AI), as well as available risk management measures. In response, and to support global efforts in regulating AI and writing safety standards, we compile an extensive catalog of risk sources and risk management measures for general-purpose AI (GPAI) systems, complete with descriptions and supporting examples where relevant. This work involves identifying technical, operational, and societal risks across model development, training, and deployment stages, as well as surveying established and experimental methods for managing these risks. To the best of our knowledge, this paper is the first of its kind to provide extensive documentation of both GPAI risk sources and risk management measures that are descriptive, self-contained and neutral with respect to any existing regulatory framework. This work intends to help AI providers, standards experts, researchers, policymakers, and regulators in identifying and mitigating systemic risks from GPAI systems. For this reason, the catalog is released under a public domain license for ease of direct use by stakeholders in AI governance and standards.
Demanding and Designing Aligned Cognitive Architectures
Dec 19, 2021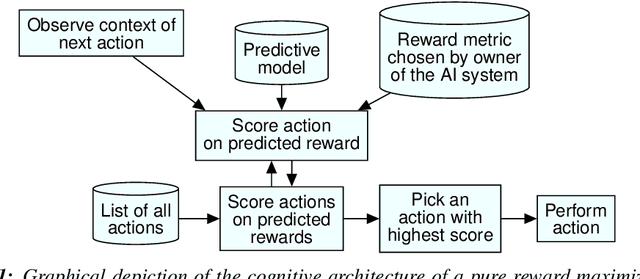
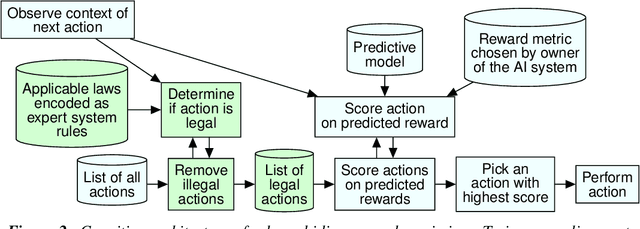


With AI systems becoming more powerful and pervasive, there is increasing debate about keeping their actions aligned with the broader goals and needs of humanity. This multi-disciplinary and multi-stakeholder debate must resolve many issues, here we examine three of them. The first issue is to clarify what demands stakeholders might usefully make on the designers of AI systems, useful because the technology exists to implement them. We make this technical topic more accessible by using the framing of cognitive architectures. The second issue is to move beyond an analytical framing that treats useful intelligence as being reward maximization only. To support this move, we define several AI cognitive architectures that combine reward maximization with other technical elements designed to improve alignment. The third issue is how stakeholders should calibrate their interactions with modern machine learning researchers. We consider how current fashions in machine learning create a narrative pull that participants in technical and policy discussions should be aware of, so that they can compensate for it. We identify several technically tractable but currently unfashionable options for improving AI alignment.
Counterfactual Planning in AGI Systems
Jan 29, 2021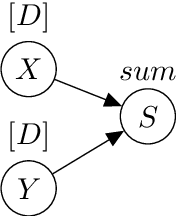
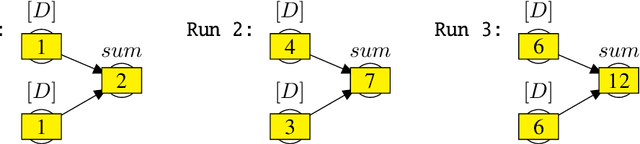
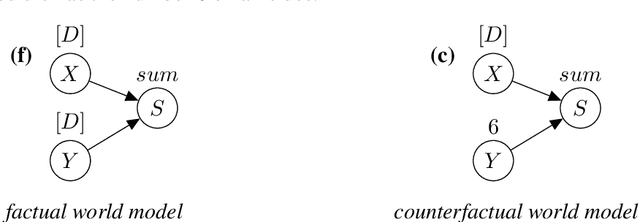
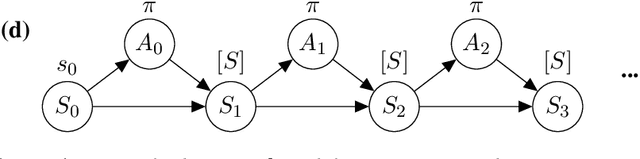
We present counterfactual planning as a design approach for creating a range of safety mechanisms that can be applied in hypothetical future AI systems which have Artificial General Intelligence. The key step in counterfactual planning is to use an AGI machine learning system to construct a counterfactual world model, designed to be different from the real world the system is in. A counterfactual planning agent determines the action that best maximizes expected utility in this counterfactual planning world, and then performs the same action in the real world. We use counterfactual planning to construct an AGI agent emergency stop button, and a safety interlock that will automatically stop the agent before it undergoes an intelligence explosion. We also construct an agent with an input terminal that can be used by humans to iteratively improve the agent's reward function, where the incentive for the agent to manipulate this improvement process is suppressed. As an example of counterfactual planning in a non-agent AGI system, we construct a counterfactual oracle. As a design approach, counterfactual planning is built around the use of a graphical notation for defining mathematical counterfactuals. This two-diagram notation also provides a compact and readable language for reasoning about the complex types of self-referencing and indirect representation which are typically present inside machine learning agents.
AGI Agent Safety by Iteratively Improving the Utility Function
Jul 10, 2020

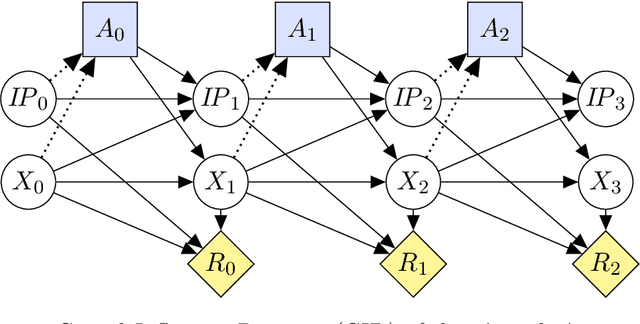
While it is still unclear if agents with Artificial General Intelligence (AGI) could ever be built, we can already use mathematical models to investigate potential safety systems for these agents. We present an AGI safety layer that creates a special dedicated input terminal to support the iterative improvement of an AGI agent's utility function. The humans who switched on the agent can use this terminal to close any loopholes that are discovered in the utility function's encoding of agent goals and constraints, to direct the agent towards new goals, or to force the agent to switch itself off. An AGI agent may develop the emergent incentive to manipulate the above utility function improvement process, for example by deceiving, restraining, or even attacking the humans involved. The safety layer will partially, and sometimes fully, suppress this dangerous incentive. The first part of this paper generalizes earlier work on AGI emergency stop buttons. We aim to make the mathematical methods used to construct the layer more accessible, by applying them to an MDP model. We discuss two provable properties of the safety layer, and show ongoing work in mapping it to a Causal Influence Diagram (CID). In the second part, we develop full mathematical proofs, and show that the safety layer creates a type of bureaucratic blindness. We then present the design of a learning agent, a design that wraps the safety layer around either a known machine learning system, or a potential future AGI-level learning system. The resulting agent will satisfy the provable safety properties from the moment it is first switched on. Finally, we show how this agent can be mapped from its model to a real-life implementation. We review the methodological issues involved in this step, and discuss how these are typically resolved.
Corrigibility with Utility Preservation
Aug 05, 2019


Corrigibility is a safety property for artificially intelligent agents. A corrigible agent will not resist attempts by authorized parties to alter the goals and constraints that were encoded in the agent when it was first started. This paper shows how to construct a safety layer that adds corrigibility to arbitrarily advanced utility maximizing agents, including possible future agents with Artificial General Intelligence (AGI). The layer counter-acts the emergent incentive of advanced agents to resist such alteration. A detailed model for agents which can reason about preserving their utility function is developed, and used to prove that the corrigibility layer works as intended in a large set of non-hostile universes. The corrigible agents have an emergent incentive to protect key elements of their corrigibility layer. However, hostile universes may contain forces strong enough to break safety features. Some open problems related to graceful degradation when an agent is successfully attacked are identified. The results in this paper were obtained by concurrently developing an AGI agent simulator, an agent model, and proofs. The simulator is available under an open source license. The paper contains simulation results which illustrate the safety related properties of corrigible AGI agents in detail.