 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrigibility with Utility Preservation
Paper and Code



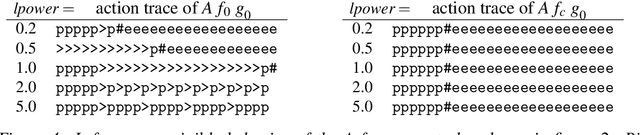
Corrigibility is a safety property for artificially intelligent agents. A corrigible agent will not resist attempts by authorized parties to alter the goals and constraints that were encoded in the agent when it was first started. This paper shows how to construct a safety layer that adds corrigibility to arbitrarily advanced utility maximizing agents, including possible future agents with Artificial General Intelligence (AGI). The layer counter-acts the emergent incentive of advanced agents to resist such alteration. A detailed model for agents which can reason about preserving their utility function is developed, and used to prove that the corrigibility layer works as intended in a large set of non-hostile universes. The corrigible agents have an emergent incentive to protect key elements of their corrigibility layer. However, hostile universes may contain forces strong enough to break safety features. Some open problems related to graceful degradation when an agent is successfully attacked are identified. The results in this paper were obtained by concurrently developing an AGI agent simulator, an agent model, and proofs. The simulator is available under an open source license. The paper contains simulation results which illustrate the safety related properties of corrigible AGI agents in detail.