 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus analysis without prior linguistic knowledge - unsupervised mining of phrases and subphrase structure
Feb 18, 2016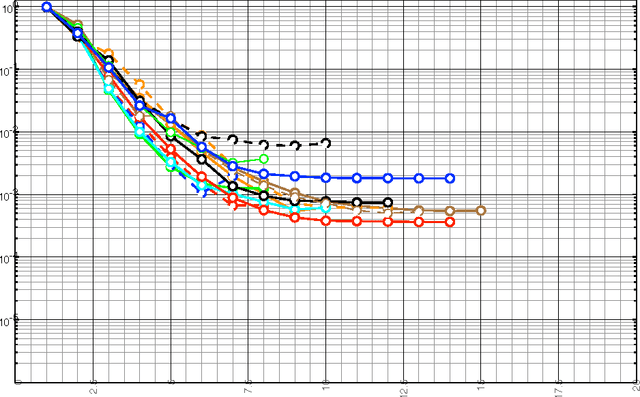
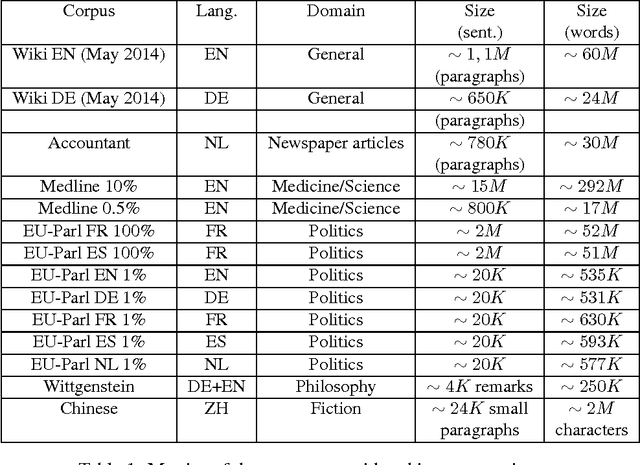
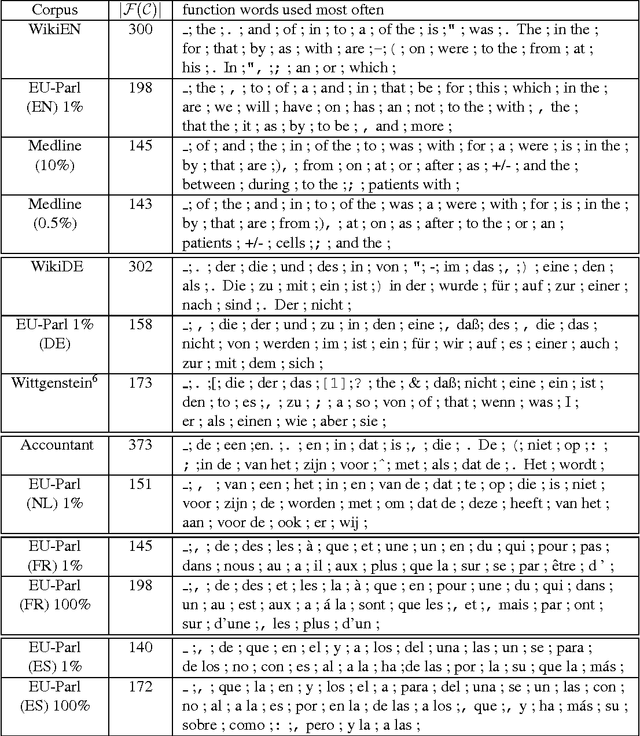

When looking at the structure of natural language, "phrases" and "words" are central notions. We consider the problem of identifying such "meaningful subparts" of language of any length and underlying composition principles in a completely corpus-based and language-independent way without using any kind of prior linguistic knowledge. Unsupervised methods for identifying "phrases", mining subphrase structure and finding words in a fully automated way are described. This can be considered as a step towards automatically computing a "general dictionary and grammar of the corpus". We hope that in the long run variants of our approach turn out to be useful for other kind of sequence data as well, such as, e.g., speech, genom sequences, or music annotation. Even if we are not primarily interested in immediate applications, results obtained for a variety of languages show that our methods are interesting for many practical tasks in text mining, terminology extraction and lexicography, search engine technology, and related fields.
Good parts first - a new algorithm for approximate search in lexica and string databases
Dec 03, 2015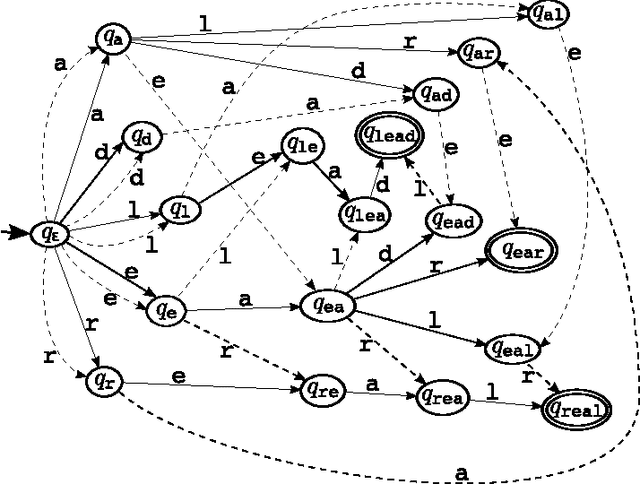
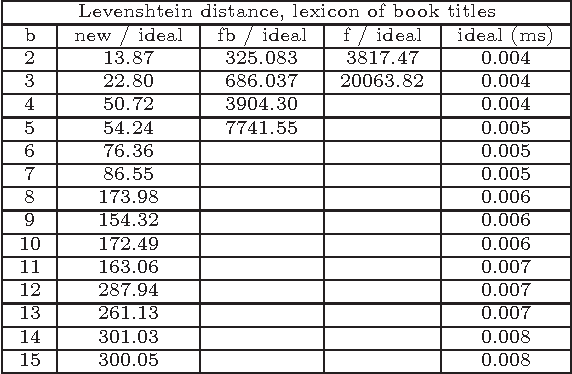
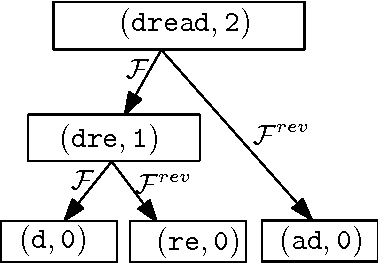
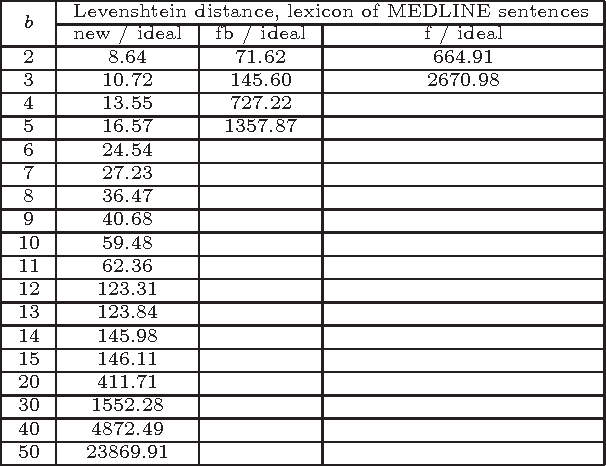
We present a new efficient method for approximate search in electronic lexica. Given an input string (the pattern) and a similarity threshold, the algorithm retrieves all entries of the lexicon that are sufficiently similar to the pattern. Search is organized in subsearches that always start with an exact partial match where a substring of the input pattern is aligned with a substring of a lexicon word. Afterwards this partial match is extended stepwise to larger substrings. For aligning further parts of the pattern with corresponding parts of lexicon entries, more errors are tolerated at each subsequent step. For supporting this alignment order, which may start at any part of the pattern, the lexicon is represented as a structure that enables immediate access to any substring of a lexicon word and permits the extension of such substrings in both directions. Experimental evaluations of the approximate search procedure are given that show significant efficiency improvements compared to existing techniques. Since the technique can be used for large error bounds it offers interesting possibilities for approximate search in special collections of "long" strings, such as phrases, sentences, or book ti
Conjunctive Queries over Trees
Feb 02, 2006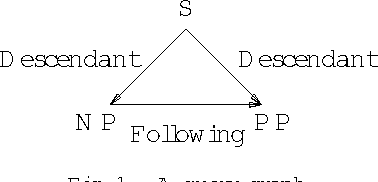
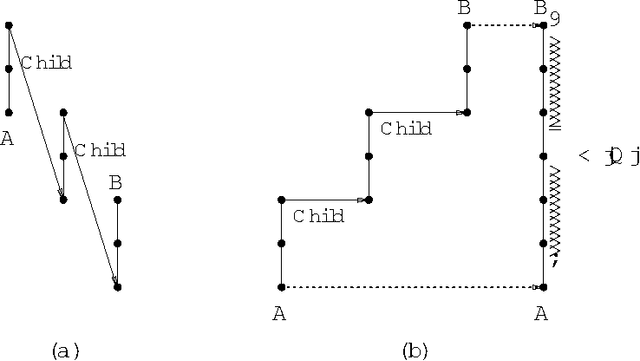
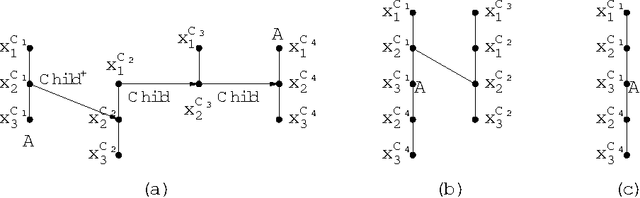
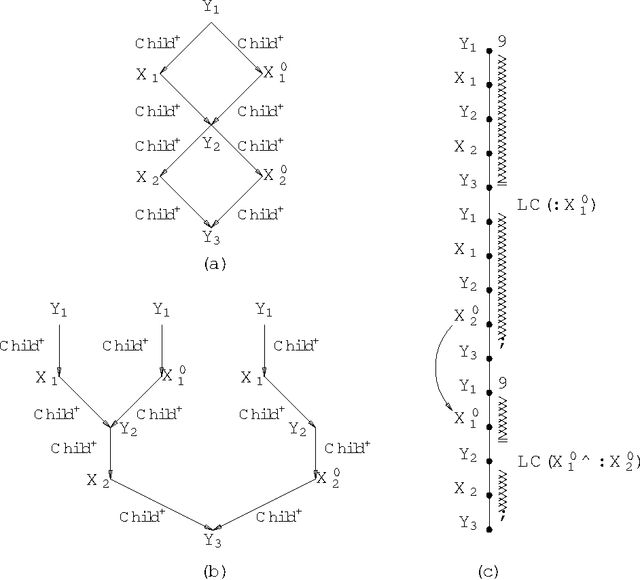
We study the complexity and expressive power of conjunctive queries over unranked labeled trees represented using a variety of structure relations such as ``child'', ``descendant'', and ``following'' as well as unary relations for node labels. We establish a framework for characterizing structures representing trees for which conjunctive queries can be evaluated efficiently. Then we completely chart the tractability frontier of the problem and establish a dichotomy theorem for our axis relations, i.e., we find all subset-maximal sets of axes for which query evaluation is in polynomial time and show that for all other cases, query evaluation is NP-complete. All polynomial-time results are obtained immediately using the proof techniques from our framework. Finally, we study the expressiveness of conjunctive queries over trees and show that for each conjunctive query, there is an equivalent acyclic positive query (i.e., a set of acyclic conjunctive queries), but that in general this query is not of polynomial size.