 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus analysis without prior linguistic knowledge - unsupervised mining of phrases and subphrase structure
Paper and Code
Feb 18, 2016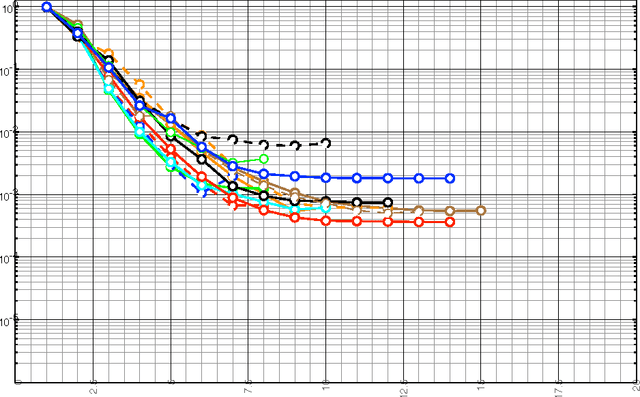
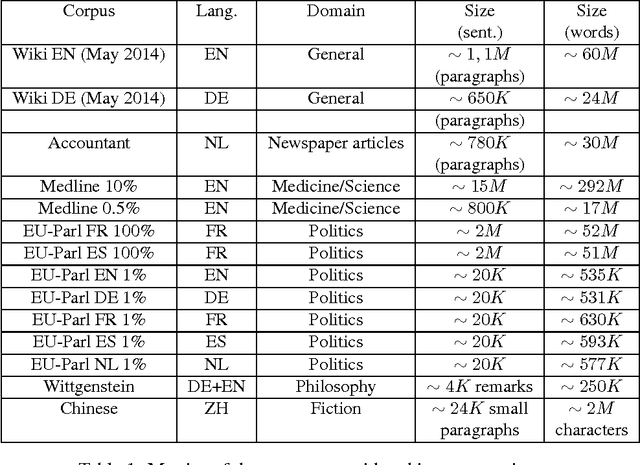
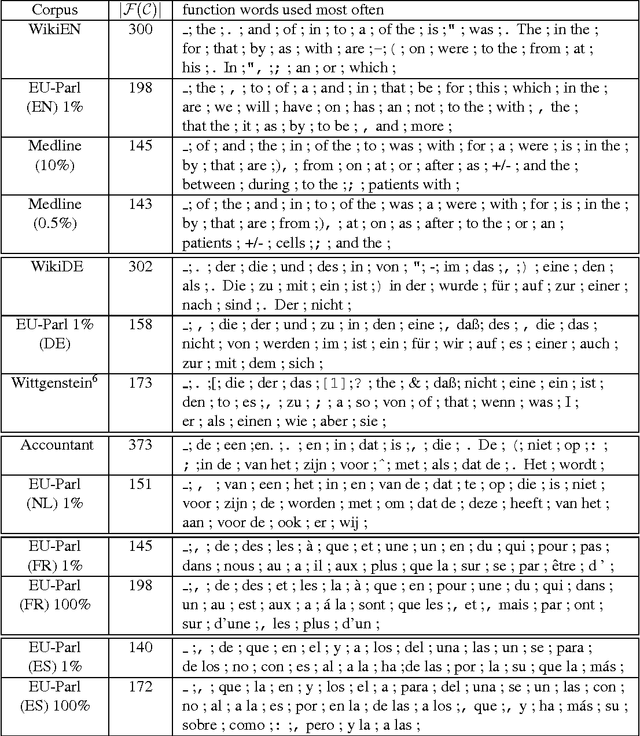

When looking at the structure of natural language, "phrases" and "words" are central notions. We consider the problem of identifying such "meaningful subparts" of language of any length and underlying composition principles in a completely corpus-based and language-independent way without using any kind of prior linguistic knowledge. Unsupervised methods for identifying "phrases", mining subphrase structure and finding words in a fully automated way are described. This can be considered as a step towards automatically computing a "general dictionary and grammar of the corpus". We hope that in the long run variants of our approach turn out to be useful for other kind of sequence data as well, such as, e.g., speech, genom sequences, or music annotation. Even if we are not primarily interested in immediate applications, results obtained for a variety of languages show that our methods are interesting for many practical tasks in text mining, terminology extraction and lexicography, search engine technology, and related fields.