 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransitivity, Time Consumption, and Quality of Preference Judgments in Crowdsourcing
Apr 18, 2021
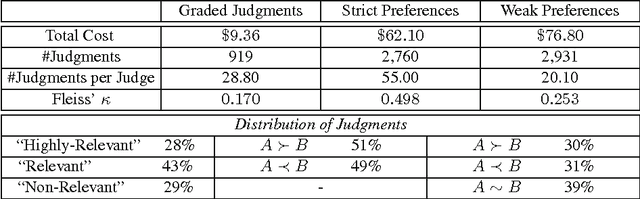
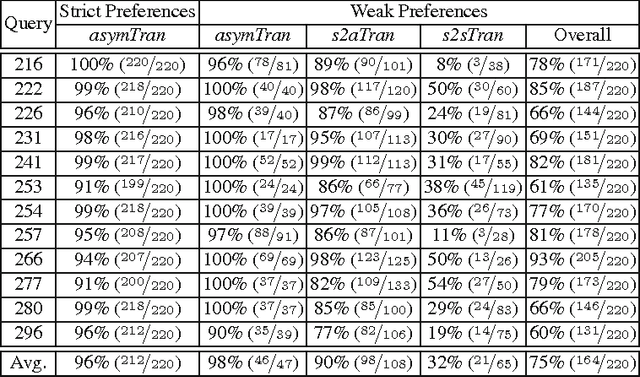
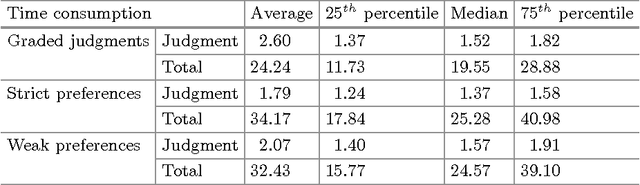
Preference judgments have been demonstrated as a better alternative to graded judgments to assess the relevance of documents relative to queries. Existing work has verified transitivity among preference judgments when collected from trained judges, which reduced the number of judgments dramatically. Moreover, strict preference judgments and weak preference judgments, where the latter additionally allow judges to state that two documents are equally relevant for a given query, are both widely used in literature. However, whether transitivity still holds when collected from crowdsourcing, i.e., whether the two kinds of preference judgments behave similarly remains unclear. In this work, we collect judgments from multiple judges using a crowdsourcing platform and aggregate them to compare the two kinds of preference judgments in terms of transitivity, time consumption, and quality. That is, we look into whether aggregated judgments are transitive, how long it takes judges to make them, and whether judges agree with each other and with judgments from TREC. Our key findings are that only strict preference judgments are transitive. Meanwhile, weak preference judgments behave differently in terms of transitivity, time consumption, as well as of quality of judgment.
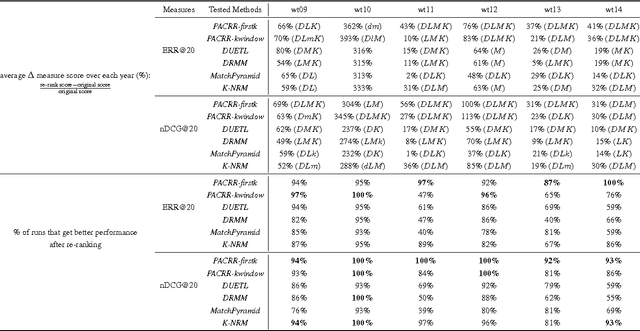
Co-PACRR: A Context-Aware Neural IR Model for Ad-hoc Retrieval
Nov 28, 2017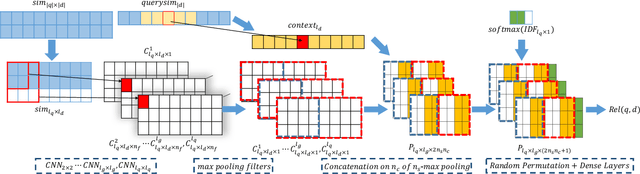

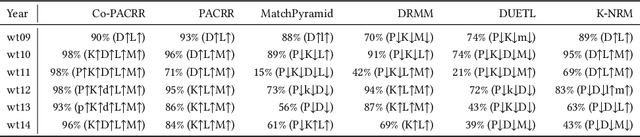
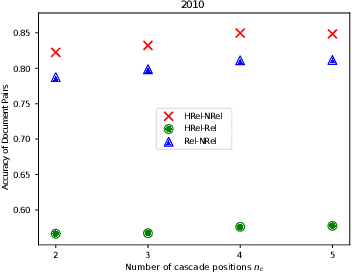
Neural IR models, such as DRMM and PACRR, have achieved strong results by successfully capturing relevance matching signals. We argue that the context of these matching signals is also important. Intuitively, when extracting, modeling, and combining matching signals, one would like to consider the surrounding text (local context) as well as other signals from the same document that can contribute to the overall relevance score. In this work, we highlight three potential shortcomings caused by not considering context information and propose three neural ingredients to address them: a disambiguation component, cascade k-max pooling, and a shuffling combination layer. Incorporating these components into the PACRR model yields Co-PACRR, a novel context-aware neural IR model. Extensive comparisons with established models on Trec Web Track data confirm that the proposed model can achieve superior search results. In addition, an ablation analysis is conducted to gain insights into the impact of and interactions between different components. We release our code to enable future comparisons.
PACRR: A Position-Aware Neural IR Model for Relevance Matching
Jul 21, 2017

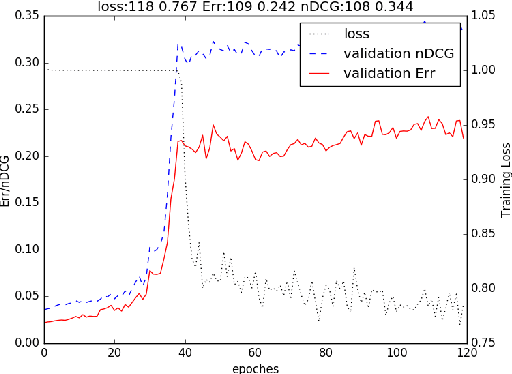
In order to adopt deep learning for information retrieval, models are needed that can capture all relevant information required to assess the relevance of a document to a given user query. While previous works have successfully captured unigram term matches, how to fully employ position-dependent information such as proximity and term dependencies has been insufficiently explored. In this work, we propose a novel neural IR model named PACRR aiming at better modeling position-dependent interactions between a query and a document. Extensive experiments on six years' TREC Web Track data confirm that the proposed model yields better results under multiple benchmarks.
Knowledge Questions from Knowledge Graphs
Nov 01, 2016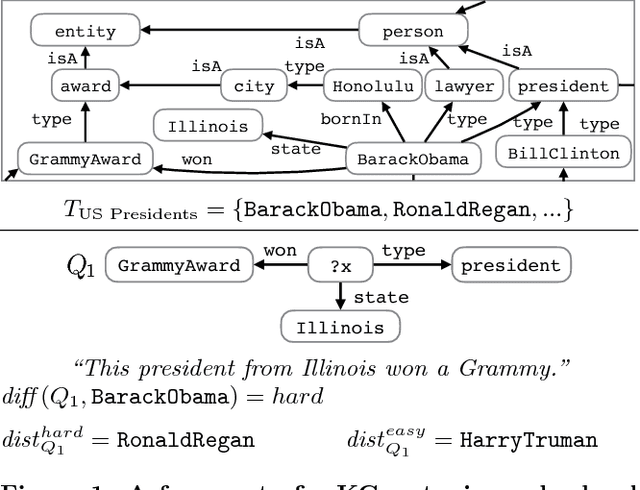
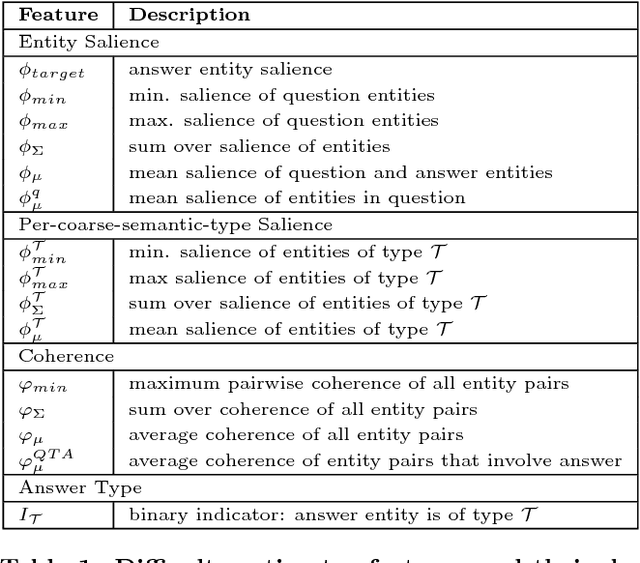
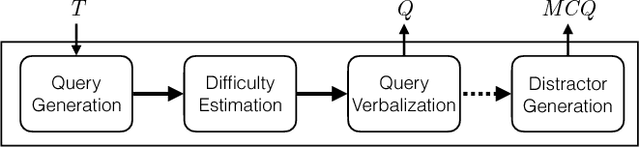
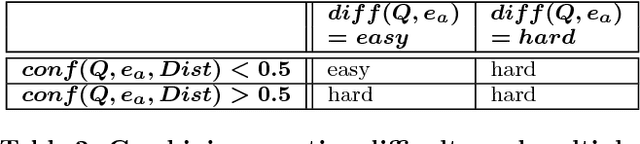
We address the novel problem of automatically generating quiz-style knowledge questions from a knowledge graph such as DBpedia. Questions of this kind have ample applications, for instance, to educate users about or to evaluate their knowledge in a specific domain. To solve the problem, we propose an end-to-end approach. The approach first selects a named entity from the knowledge graph as an answer. It then generates a structured triple-pattern query, which yields the answer as its sole result. If a multiple-choice question is desired, the approach selects alternative answer options. Finally, our approach uses a template-based method to verbalize the structured query and yield a natural language question. A key challenge is estimating how difficult the generated question is to human users. To do this, we make use of historical data from the Jeopardy! quiz show and a semantically annotated Web-scale document collection, engineer suitable features, and train a logistic regression classifier to predict question difficulty. Experiments demonstrate the viability of our overall approach.