 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Adaptive Stochastic Gradient Optimization
Nov 06, 2018
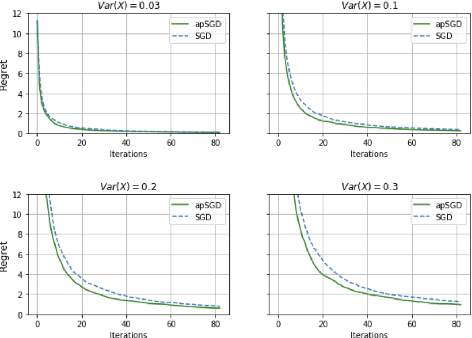

Adaptive moment methods have been remarkably successful in deep learning optimization, particularly in the presence of noisy and/or sparse gradients. We further the advantages of adaptive moment techniques by proposing a family of double adaptive stochastic gradient methods~\textsc{DASGrad}. They leverage the complementary ideas of the adaptive moment algorithms widely used by deep learning community, and recent advances in adaptive probabilistic algorithms.We analyze the theoretical convergence improvements of our approach in a stochastic convex optimization setting, and provide empirical validation of our findings with convex and non convex objectives. We observe that the benefits of~\textsc{DASGrad} increase with the model complexity and variability of the gradients, and we explore the resulting utility in extensions of distribution-matching multitask learning.