 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Dropout -- A Simple Approach for Enabling Federated Learning on Resource Constrained Devices
Sep 30, 2021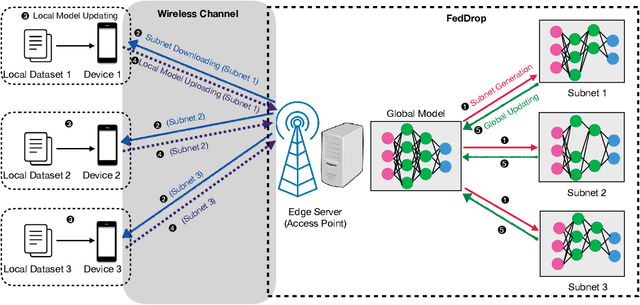


Federated learning (FL) is a popular framework for training an AI model using distributed mobile data in a wireless network. It features data parallelism by distributing the learning task to multiple edge devices while attempting to preserve their local-data privacy. One main challenge confronting practical FL is that resource constrained devices struggle with the computation intensive task of updating of a deep-neural network model. To tackle the challenge, in this paper, a federated dropout (FedDrop) scheme is proposed building on the classic dropout scheme for random model pruning. Specifically, in each iteration of the FL algorithm, several subnets are independently generated from the global model at the server using dropout but with heterogeneous dropout rates (i.e., parameter-pruning probabilities), each of which is adapted to the state of an assigned channel. The subsets are downloaded to associated devices for updating. Thereby, FdeDrop reduces both the communication overhead and devices' computation loads compared with the conventional FL while outperforming the latter in the case of overfitting and also the FL scheme with uniform dropout (i.e., identical subsets).
Adaptive Subcarrier, Parameter, and Power Allocation for Partitioned Edge Learning Over Broadband Channels
Oct 08, 2020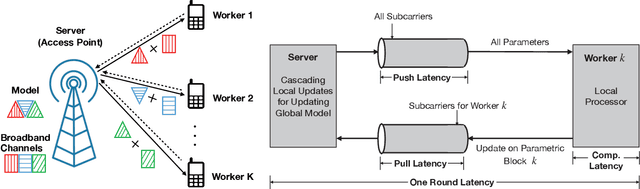
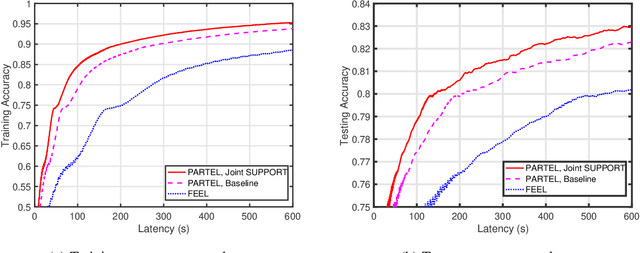
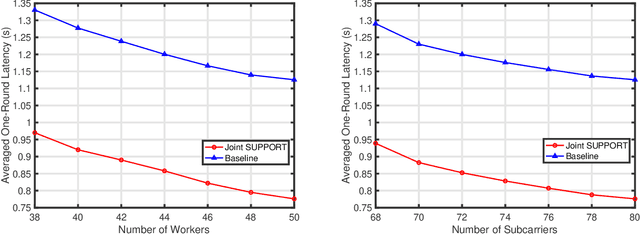
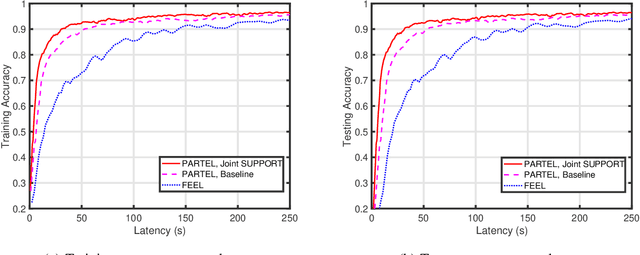
A main edge learning paradigm, called partitioned edge learning (PARTEL), is considered. It supports the distributed training of a large-scale AI model by dynamically partitioning the model and allocating the resultant parametric blocks to different devices for updating. Then devices upload the updates to a server where they are assembled and applied to updating the model. The two steps are iterated till the model converges. In this work, we consider the efficient joint management of parameter allocation and radio resources to reduce the learning latency of PARTEL, when deployed in a broadband system using orthogonal frequency-division multiplexing (OFDM). Specifically, the policies for joint subcarrier, parameter, and power allocation (SUPPORT) are optimized under the criterion of minimum latency. Two cases are considered. First, for the case of decomposable models (e.g., logistic regression or support vector machine), the latency-minimization problem is a mixed-integer program and non-convex. Due to its intractability, we develop a practical solution by 1) relaxing the binary subcarrier-assignment decisions and 2) transforming the relaxed problem into a convex problem of model size maximization under a latency constraint nested in a simple search for the target model size. By deriving the properties of the convex problem, a low-complexity algorithm is designed to compute the SUPPORT policy. Second, consider the case of convolutional neural network (CNN) models which can be trained using PARTEL by introducing some auxiliary variables. This, however, introduces constraints on model partitioning reducing the granularity of parameter allocation. The preceding policy is extended to CNN models by applying the proposed techniques of load rounding and proportional adjustment to rein in latency expansion caused by the load granularity constraints.