 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdioLink: Retrieving Meaning Beyond Words Across Idiomatic and Literal Expressions
May 21, 2026Idioms pose a fundamental challenge for language models, as their meaning cannot be inferred from surface form alone. Understanding such expressions, therefore, requires semantic abstraction beyond lexical overlap. We introduce IdioLink, a retrieval benchmark designed to test whether models can link idiomatic expressions to conceptually equivalent meanings expressed in literal or paraphrased forms. IdioLink comprises 10,700 documents and 2,140 queries, spanning 107 idioms with both literal and figurative uses. Each document and query is annotated with spans that convey the core meaning. Evaluating strong embedding baselines (e.g., BGE, E5, Contriever, and Qwen), we show that current models struggle to retrieve equivalent meanings across divergent surface realizations, relying instead on topical and shallow semantic cues. IdioLink exposes key gaps in idiom-aware semantic retrieval and provides a challenging testbed for future models.
Building Patient Journeys in Hebrew: A Language Model for Clinical Timeline Extraction
Dec 12, 2025



We present a new Hebrew medical language model designed to extract structured clinical timelines from electronic health records, enabling the construction of patient journeys. Our model is based on DictaBERT 2.0 and continually pre-trained on over five million de-identified hospital records. To evaluate its effectiveness, we introduce two new datasets -- one from internal medicine and emergency departments, and another from oncology -- annotated for event temporal relations. Our results show that our model achieves strong performance on both datasets. We also find that vocabulary adaptation improves token efficiency and that de-identification does not compromise downstream performance, supporting privacy-conscious model development. The model is made available for research use under ethical restrictions.
Training a Bilingual Language Model by Mapping Tokens onto a Shared Character Space
Feb 25, 2024


We train a bilingual Arabic-Hebrew language model using a transliterated version of Arabic texts in Hebrew, to ensure both languages are represented in the same script. Given the morphological, structural similarities, and the extensive number of cognates shared among Arabic and Hebrew, we assess the performance of a language model that employs a unified script for both languages, on machine translation which requires cross-lingual knowledge. The results are promising: our model outperforms a contrasting model which keeps the Arabic texts in the Arabic script, demonstrating the efficacy of the transliteration step. Despite being trained on a dataset approximately 60% smaller than that of other existing language models, our model appears to deliver comparable performance in machine translation across both translation directions.
Supporting Undotted Arabic with Pre-trained Language Models
Nov 18, 2021
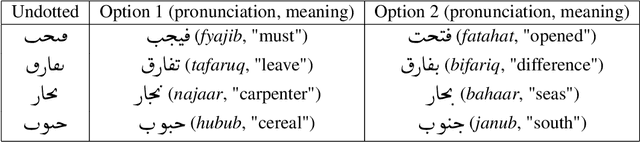

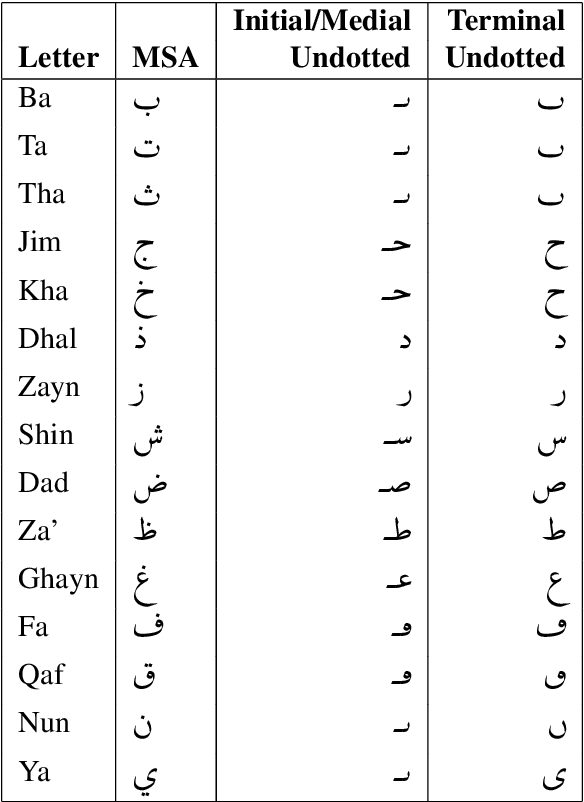
We observe a recent behaviour on social media, in which users intentionally remove consonantal dots from Arabic letters, in order to bypass content-classification algorithms. Content classification is typically done by fine-tuning pre-trained language models, which have been recently employed by many natural-language-processing applications. In this work we study the effect of applying pre-trained Arabic language models on "undotted" Arabic texts. We suggest several ways of supporting undotted texts with pre-trained models, without additional training, and measure their performance on two Arabic natural-language-processing downstream tasks. The results are encouraging; in one of the tasks our method shows nearly perfect performance.
Automatic Metaphor Interpretation Using Word Embeddings
Oct 06, 2020


We suggest a model for metaphor interpretation using word embeddings trained over a relatively large corpus. Our system handles nominal metaphors, like "time is money". It generates a ranked list of potential interpretations of given metaphors. Candidate meanings are drawn from collocations of the topic ("time") and vehicle ("money") components, automatically extracted from a dependency-parsed corpus. We explore adding candidates derived from word association norms (common human responses to cues). Our ranking procedure considers similarity between candidate interpretations and metaphor components, measured in a semantic vector space. Lastly, a clustering algorithm removes semantically related duplicates, thereby allowing other candidate interpretations to attain higher rank. We evaluate using a set of annotated metaphors.
Semantic Characteristics of Schizophrenic Speech
Apr 16, 2019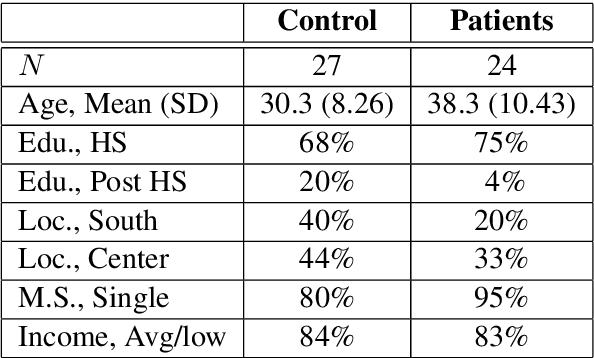
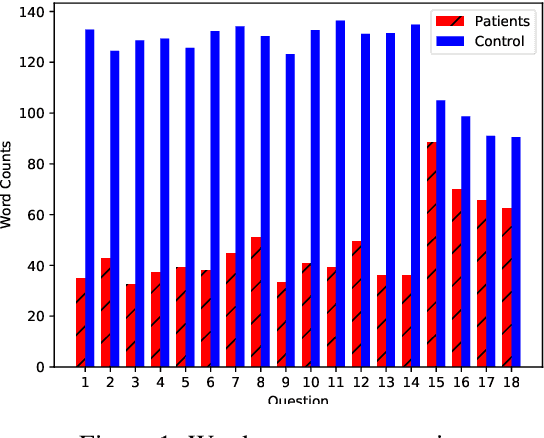

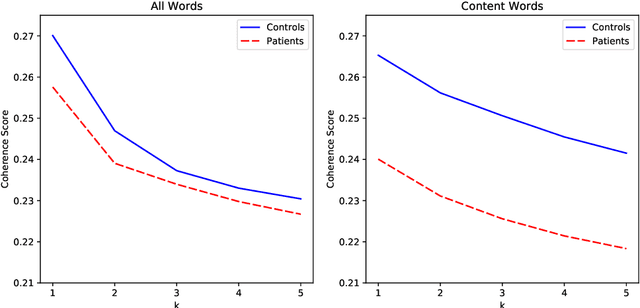
Natural language processing tools are used to automatically detect disturbances in transcribed speech of schizophrenia inpatients who speak Hebrew. We measure topic mutation over time and show that controls maintain more cohesive speech than inpatients. We also examine differences in how inpatients and controls use adjectives and adverbs to describe content words and show that the ones used by controls are more common than the those of inpatients. We provide experimental results and show their potential for automatically detecting schizophrenia in patients by means only of their speech patterns.