 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Bilingual Language Model by Mapping Tokens onto a Shared Character Space
Feb 25, 2024


We train a bilingual Arabic-Hebrew language model using a transliterated version of Arabic texts in Hebrew, to ensure both languages are represented in the same script. Given the morphological, structural similarities, and the extensive number of cognates shared among Arabic and Hebrew, we assess the performance of a language model that employs a unified script for both languages, on machine translation which requires cross-lingual knowledge. The results are promising: our model outperforms a contrasting model which keeps the Arabic texts in the Arabic script, demonstrating the efficacy of the transliteration step. Despite being trained on a dataset approximately 60% smaller than that of other existing language models, our model appears to deliver comparable performance in machine translation across both translation directions.
Supporting Undotted Arabic with Pre-trained Language Models
Nov 18, 2021
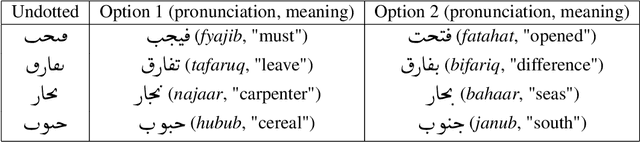

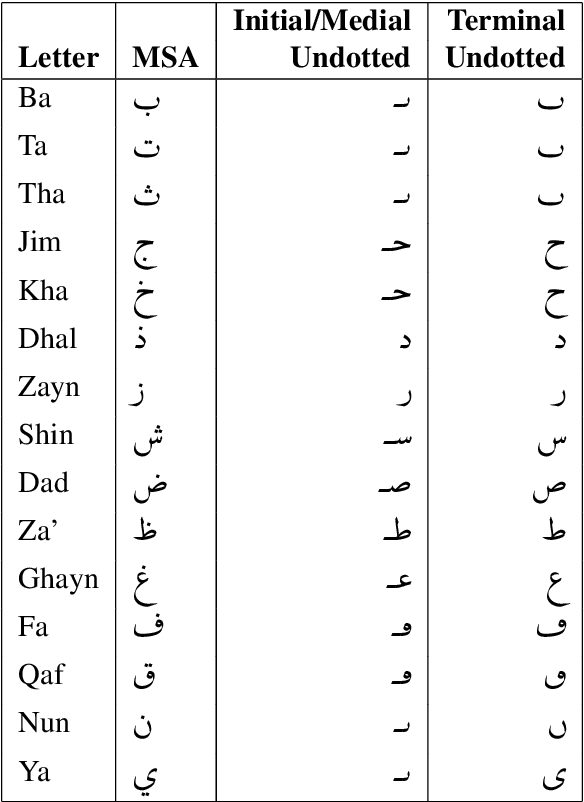
We observe a recent behaviour on social media, in which users intentionally remove consonantal dots from Arabic letters, in order to bypass content-classification algorithms. Content classification is typically done by fine-tuning pre-trained language models, which have been recently employed by many natural-language-processing applications. In this work we study the effect of applying pre-trained Arabic language models on "undotted" Arabic texts. We suggest several ways of supporting undotted texts with pre-trained models, without additional training, and measure their performance on two Arabic natural-language-processing downstream tasks. The results are encouraging; in one of the tasks our method shows nearly perfect performance.