 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric compression of invariant manifolds in neural nets
Aug 28, 2020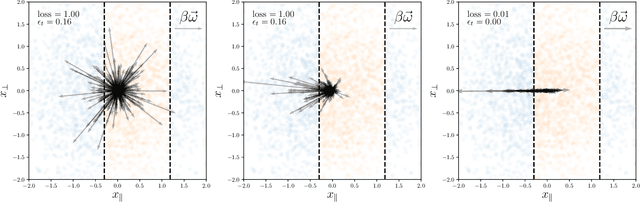
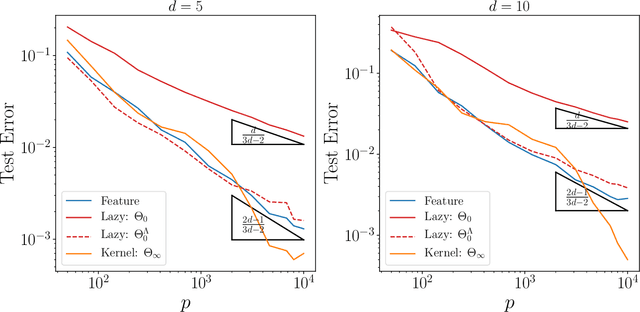
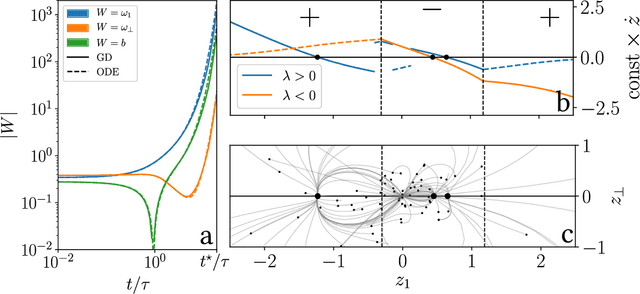
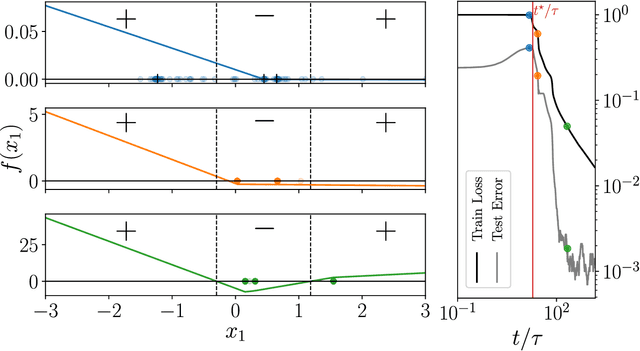
We study how neural networks compress uninformative input space in models where data lie in $d$ dimensions, but whose label only vary within a linear manifold of dimension $d_\parallel < d$. We show that for a one-hidden layer network initialized with infinitesimal weights (i.e. in the \textit{feature learning} regime) trained with gradient descent, the uninformative $d_\perp=d-d_\parallel$ space is compressed by a factor $\lambda\sim \sqrt{p}$, where $p$ is the size of the training set. We quantify the benefit of such a compression on the test error $\epsilon$. For large initialization of the weights (the \textit{lazy training} regime), no compression occurs and for regular boundaries separating labels we find that $\epsilon \sim p^{-\beta}$, with $\beta_\text{Lazy} = d / (3d-2)$. Compression improves the learning curves so that $\beta_\text{Feature} = (2d-1)/(3d-2)$ if $d_\parallel = 1$ and $\beta_\text{Feature} = (d + d_\perp/2)/(3d-2)$ if $d_\parallel > 1$. We test these predictions for a stripe model where boundaries are parallel interfaces ($d_\parallel=1$) as well as for a cylindrical boundary ($d_\parallel=2$). Next we show that compression shapes the Neural Tangent Kernel (NTK) evolution in time, so that its top eigenvectors become more informative and display a larger projection on the labels. Consequently, kernel learning with the frozen NTK at the end of training outperforms the initial NTK. We confirm these predictions both for a one-hidden layer FC network trained on the stripe model and for a 16-layers CNN trained on MNIST, for which we also find $\beta_\text{Feature}>\beta_\text{Lazy}$. The great similarities found in these two cases support that compression is central to the training of MNIST, and puts forward kernel-PCA on the evolving NTK as a useful diagnostic of compression in deep nets.