 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Social Media Post Popularity Prediction with Visual Content
May 08, 2024Our study presents a framework for predicting image-based social media content popularity that focuses on addressing complex image information and a hierarchical data structure. We utilize the Google Cloud Vision API to effectively extract key image and color information from users' postings, achieving 6.8% higher accuracy compared to using non-image covariates alone. For prediction, we explore a wide range of prediction models, including Linear Mixed Model, Support Vector Regression, Multi-layer Perceptron, Random Forest, and XGBoost, with linear regression as the benchmark. Our comparative study demonstrates that models that are capable of capturing the underlying nonlinear interactions between covariates outperform other methods.
Transformer Network-based Reinforcement Learning Method for Power Distribution Network (PDN) Optimization of High Bandwidth Memory (HBM)
Mar 29, 2022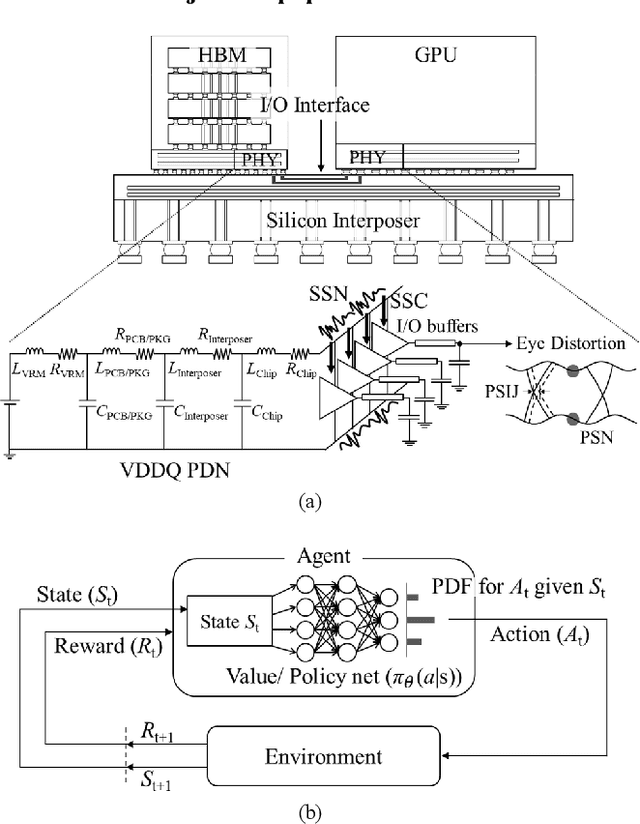
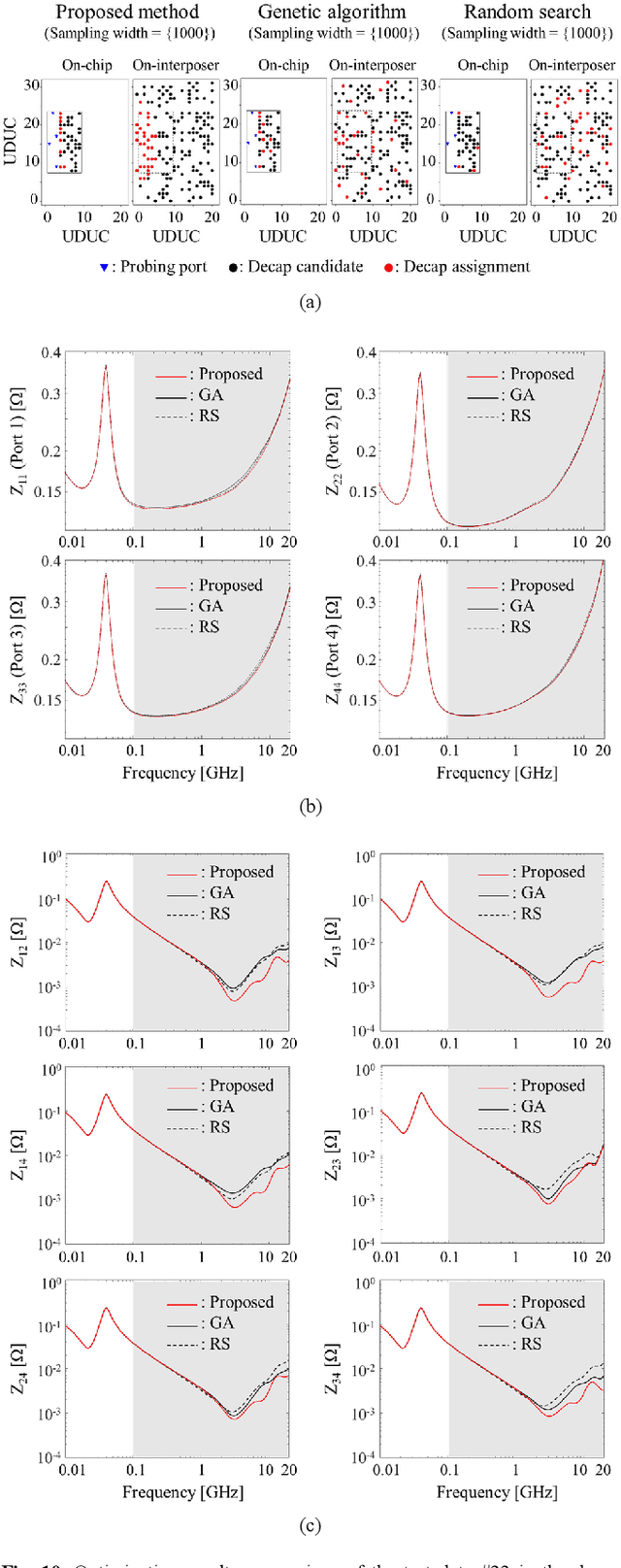
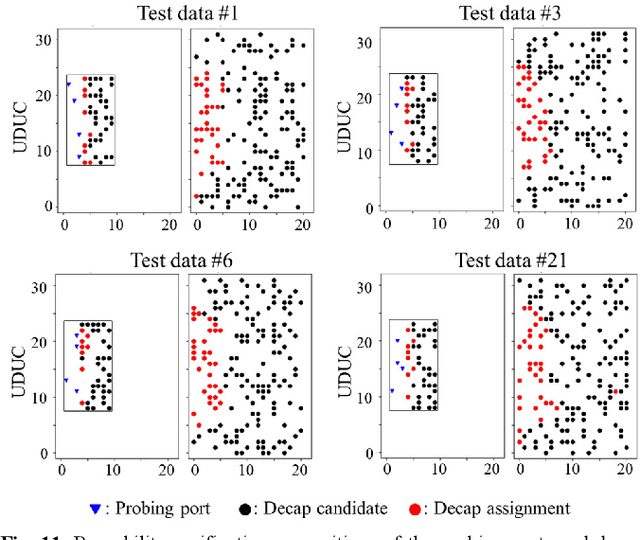
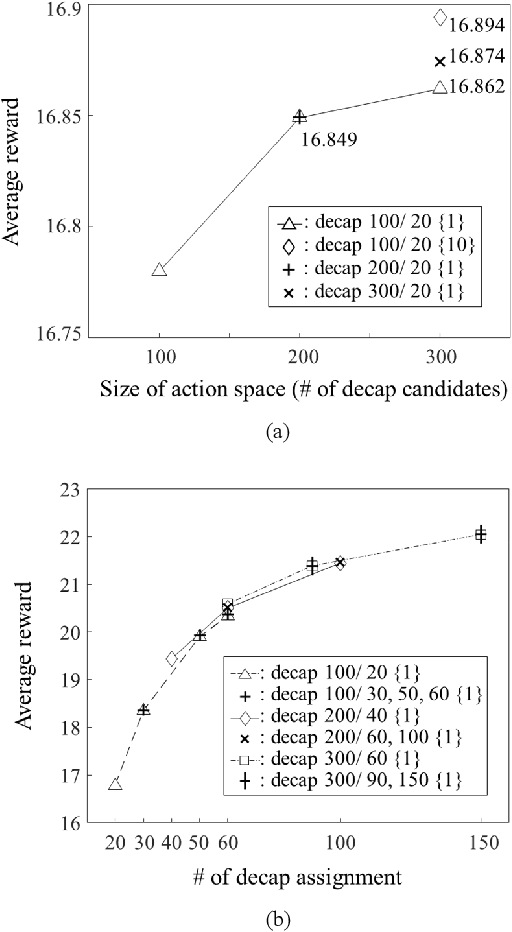
In this article, for the first time, we propose a transformer network-based reinforcement learning (RL) method for power distribution network (PDN) optimization of high bandwidth memory (HBM). The proposed method can provide an optimal decoupling capacitor (decap) design to maximize the reduction of PDN self- and transfer impedance seen at multiple ports. An attention-based transformer network is implemented to directly parameterize decap optimization policy. The optimality performance is significantly improved since the attention mechanism has powerful expression to explore massive combinatorial space for decap assignments. Moreover, it can capture sequential relationships between the decap assignments. The computing time for optimization is dramatically reduced due to the reusable network on positions of probing ports and decap assignment candidates. This is because the transformer network has a context embedding process to capture meta-features including probing ports positions. In addition, the network is trained with randomly generated data sets. Therefore, without additional training, the trained network can solve new decap optimization problems. The computing time for training and data cost are critically decreased due to the scalability of the network. Thanks to its shared weight property, the network can adapt to a larger scale of problems without additional training. For verification, we compare the results with conventional genetic algorithm (GA), random search (RS), and all the previous RL-based methods. As a result, the proposed method outperforms in all the following aspects: optimality performance, computing time, and data efficiency.