 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFN-TS: Thompson Sampling for Contextual Bandits via Prior-Data Fitted Networks
May 11, 2026Thompson sampling is a widely used strategy for contextual bandits: at each round, it samples a reward function from a Bayesian posterior and acts greedily under that sample. Prior-data fitted networks (PFNs), such as TabPFN v2+ and TabICL v2, are attractive candidates for this purpose because they approximate Bayesian posterior predictive distributions in a single forward pass. However, PFNs predict noisy future rewards, while Thompson sampling requires uncertainty over the latent mean reward function. We propose PFN-TS, a Thompson sampling algorithm that converts PFN posterior predictives into mean-reward samples using a subsampled predictive central limit theorem. The method estimates posterior variance from a geometric grid of $O(\log n)$ dataset prefixes rather than the full $O(n)$ predictive sequence used in previous predictive-sequence approaches, and reuses TabICL's cached representations across rounds. We prove consistency of the subsampled variance estimator and give a Bayesian regret bound that decomposes PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms. Empirically, PFN-TS achieves the best average rank across nonlinear synthetic and OpenML classification-to-bandit benchmarks, remains competitive on linear and BART-generated rewards, and attains the highest estimated policy value in an offline mobile-health evaluation. Code is available at https://anonymous.4open.science/r/PFN_TS-36ED/.
A principled framework for uncertainty decomposition in TabPFN
Feb 04, 2026TabPFN is a transformer that achieves state-of-the-art performance on supervised tabular tasks by amortizing Bayesian prediction into a single forward pass. However, there is currently no method for uncertainty decomposition in TabPFN. Because it behaves, in an idealised limit, as a Bayesian in-context learner, we cast the decomposition challenge as a Bayesian predictive inference (BPI) problem. The main computational tool in BPI, predictive Monte Carlo, is challenging to apply here as it requires simulating unmodeled covariates. We therefore pursue the asymptotic alternative, filling a gap in the theory for supervised settings by proving a predictive CLT under quasi-martingale conditions. We derive variance estimators determined by the volatility of predictive updates along the context. The resulting credible bands are fast to compute, target epistemic uncertainty, and achieve near-nominal frequentist coverage. For classification, we further obtain an entropy-based uncertainty decomposition.
Temperature Optimization for Bayesian Deep Learning
Oct 08, 2024
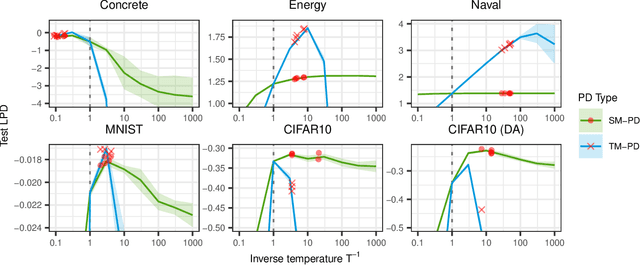
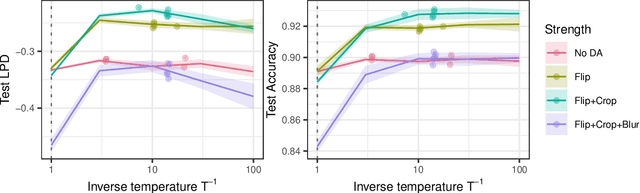

The Cold Posterior Effect (CPE) is a phenomenon in Bayesian Deep Learning (BDL), where tempering the posterior to a cold temperature often improves the predictive performance of the posterior predictive distribution (PPD). Although the term `CPE' suggests colder temperatures are inherently better, the BDL community increasingly recognizes that this is not always the case. Despite this, there remains no systematic method for finding the optimal temperature beyond grid search. In this work, we propose a data-driven approach to select the temperature that maximizes test log-predictive density, treating the temperature as a model parameter and estimating it directly from the data. We empirically demonstrate that our method performs comparably to grid search, at a fraction of the cost, across both regression and classification tasks. Finally, we highlight the differing perspectives on CPE between the BDL and Generalized Bayes communities: while the former primarily focuses on predictive performance of the PPD, the latter emphasizes calibrated uncertainty and robustness to model misspecification; these distinct objectives lead to different temperature preferences.
Pathwise Gradient Variance Reduction with Control Variates in Variational Inference
Oct 08, 2024Variational inference in Bayesian deep learning often involves computing the gradient of an expectation that lacks a closed-form solution. In these cases, pathwise and score-function gradient estimators are the most common approaches. The pathwise estimator is often favoured for its substantially lower variance compared to the score-function estimator, which typically requires variance reduction techniques. However, recent research suggests that even pathwise gradient estimators could benefit from variance reduction. In this work, we review existing control-variates-based variance reduction methods for pathwise gradient estimators to assess their effectiveness. Notably, these methods often rely on integrand approximations and are applicable only to simple variational families. To address this limitation, we propose applying zero-variance control variates to pathwise gradient estimators. This approach offers the advantage of requiring minimal assumptions about the variational distribution, other than being able to sample from it.