 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Joint Speech Recognition and Disfluency Detection
Nov 16, 2022Disfluency detection has mainly been solved in a pipeline approach, as post-processing of speech recognition. In this study, we propose Transformer-based encoder-decoder models that jointly solve speech recognition and disfluency detection, which work in a streaming manner. Compared to pipeline approaches, the joint models can leverage acoustic information that makes disfluency detection robust to recognition errors and provide non-verbal clues. Moreover, joint modeling results in low-latency and lightweight inference. We investigate two joint model variants for streaming disfluency detection: a transcript-enriched model and a multi-task model. The transcript-enriched model is trained on text with special tags indicating the starting and ending points of the disfluent part. However, it has problems with latency and standard language model adaptation, which arise from the additional disfluency tags. We propose a multi-task model to solve such problems, which has two output layers at the Transformer decoder; one for speech recognition and the other for disfluency detection. It is modeled to be conditioned on the currently recognized token with an additional token-dependency mechanism. We show that the proposed joint models outperformed a BERT-based pipeline approach in both accuracy and latency, on both the Switchboard and the corpus of spontaneous Japanese.
Data Augmentation Methods for End-to-end Speech Recognition on Distant-Talk Scenarios
Jun 07, 2021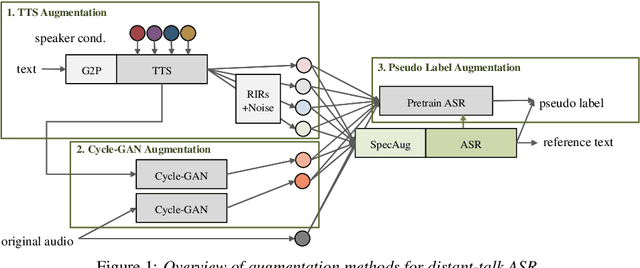



Although end-to-end automatic speech recognition (E2E ASR) has achieved great performance in tasks that have numerous paired data, it is still challenging to make E2E ASR robust against noisy and low-resource conditions. In this study, we investigated data augmentation methods for E2E ASR in distant-talk scenarios. E2E ASR models are trained on the series of CHiME challenge datasets, which are suitable tasks for studying robustness against noisy and spontaneous speech. We propose to use three augmentation methods and thier combinations: 1) data augmentation using text-to-speech (TTS) data, 2) cycle-consistent generative adversarial network (Cycle-GAN) augmentation trained to map two different audio characteristics, the one of clean speech and of noisy recordings, to match the testing condition, and 3) pseudo-label augmentation provided by the pretrained ASR module for smoothing label distributions. Experimental results using the CHiME-6/CHiME-4 datasets show that each augmentation method individually improves the accuracy on top of the conventional SpecAugment; further improvements are obtained by combining these approaches. We achieved 4.3\% word error rate (WER) reduction, which was more significant than that of the SpecAugment, when we combine all three augmentations for the CHiME-6 task.