 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTerm: Adaptive T-Distribution Estimated Robust Moments towards Noise-Robust Stochastic Gradient Optimizer
Jan 18, 2022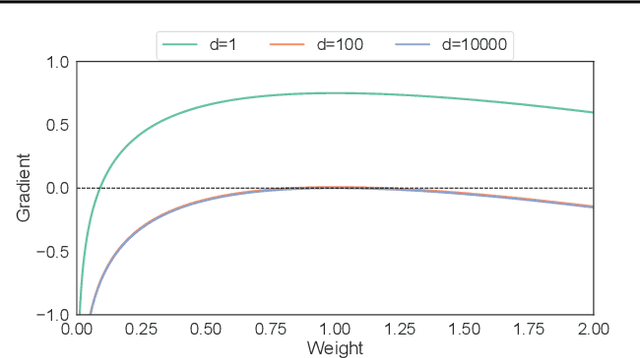
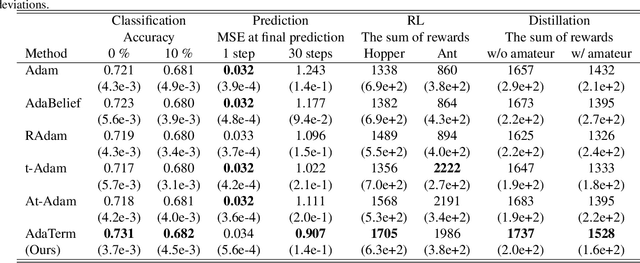
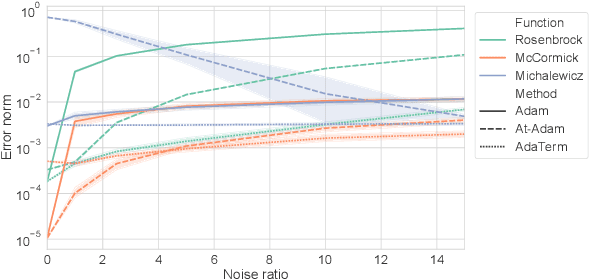
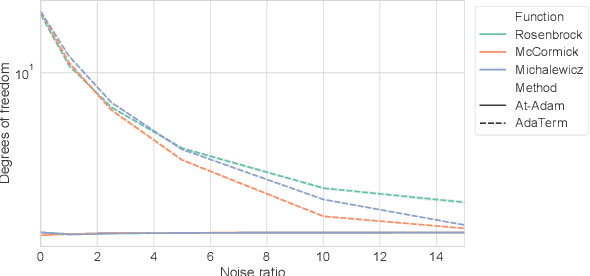
As the problems to be optimized with deep learning become more practical, their datasets inevitably contain a variety of noise, such as mislabeling and substitution by estimated inputs/outputs, which would have negative impacts on the optimization results. As a safety net, it is a natural idea to improve a stochastic gradient descent (SGD) optimizer, which updates the network parameters as the final process of learning, to be more robust to noise. The related work revealed that the first momentum utilized in the Adam-like SGD optimizers can be modified based on the noise-robust student's t-distribution, resulting in inheriting the robustness to noise. In this paper, we propose AdaTerm, which derives not only the first momentum but also all the involved statistics based on the student's t-distribution. If the computed gradients seem to probably be aberrant, AdaTerm is expected to exclude the computed gradients for updates, and reinforce the robustness for the next updates; otherwise, it updates the network parameters normally, and can relax the robustness for the next updates. With this noise-adaptive behavior, the excellent learning performance of AdaTerm was confirmed via typical optimization problems with several cases where the noise ratio would be different.
Adaptive t-Momentum-based Optimization for Unknown Ratio of Outliers in Amateur Data in Imitation Learning
Aug 02, 2021
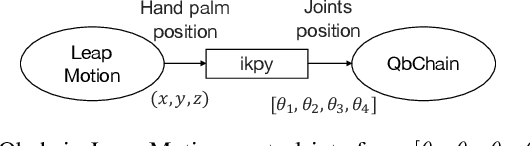
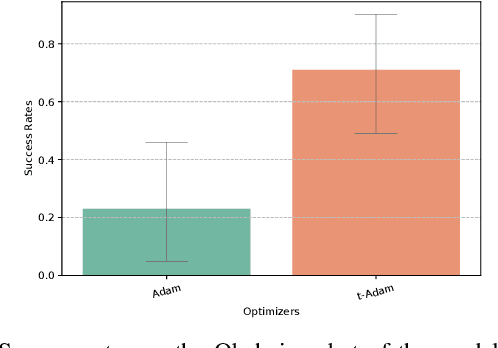
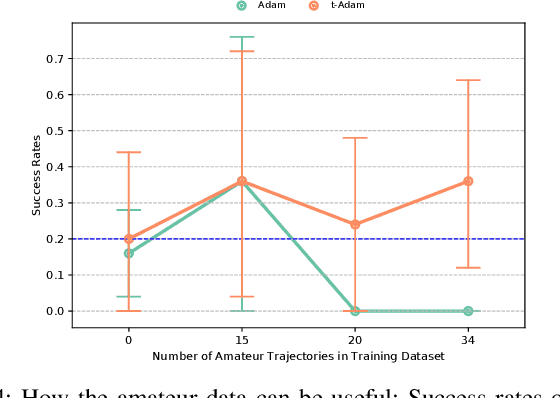
Behavioral cloning (BC) bears a high potential for safe and direct transfer of human skills to robots. However, demonstrations performed by human operators often contain noise or imperfect behaviors that can affect the efficiency of the imitator if left unchecked. In order to allow the imitators to effectively learn from imperfect demonstrations, we propose to employ the robust t-momentum optimization algorithm. This algorithm builds on the Student's t-distribution in order to deal with heavy-tailed data and reduce the effect of outlying observations. We extend the t-momentum algorithm to allow for an adaptive and automatic robustness and show empirically how the algorithm can be used to produce robust BC imitators against datasets with unknown heaviness. Indeed, the imitators trained with the t-momentum-based Adam optimizers displayed robustness to imperfect demonstrations on two different manipulation tasks with different robots and revealed the capability to take advantage of the additional data while reducing the adverse effect of non-optimal behaviors.
TAdam: A Robust Stochastic Gradient Optimizer
Mar 03, 2020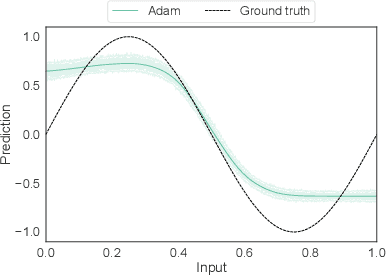
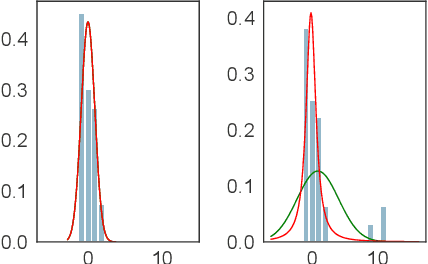
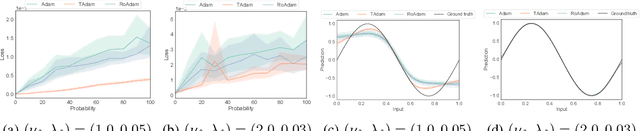
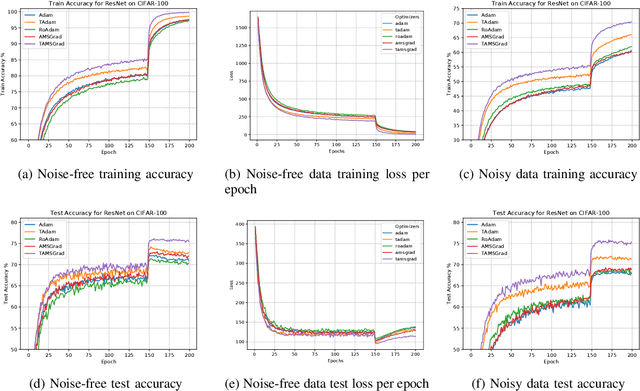
Machine learning algorithms aim to find patterns from observations, which may include some noise, especially in robotics domain. To perform well even with such noise, we expect them to be able to detect outliers and discard them when needed. We therefore propose a new stochastic gradient optimization method, whose robustness is directly built in the algorithm, using the robust student-t distribution as its core idea. Adam, the popular optimization method, is modified with our method and the resultant optimizer, so-called TAdam, is shown to effectively outperform Adam in terms of robustness against noise on diverse task, ranging from regression and classification to reinforcement learning problems. The implementation of our algorithm can be found at https://github.com/Mahoumaru/TAdam.git