 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTerm: Adaptive T-Distribution Estimated Robust Moments towards Noise-Robust Stochastic Gradient Optimizer
Paper and Code
Jan 18, 2022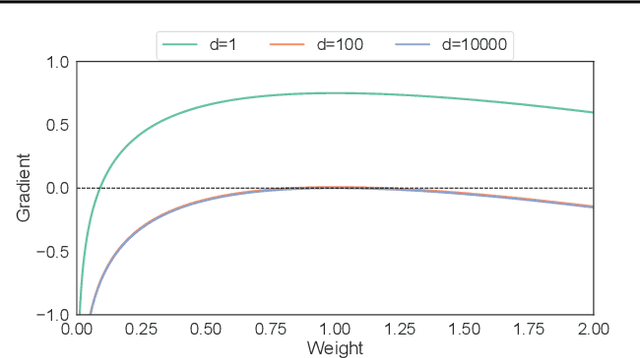
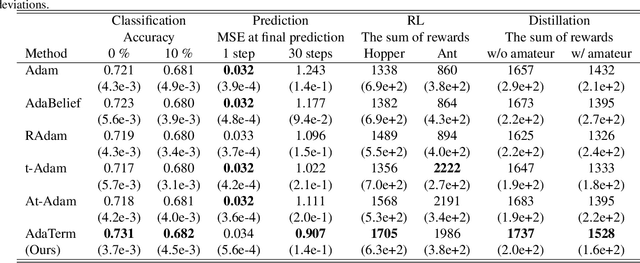
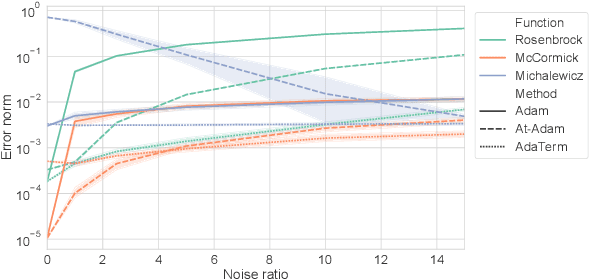
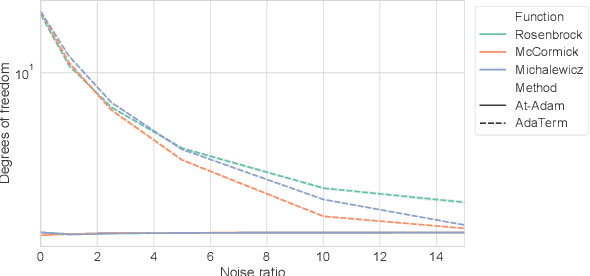
As the problems to be optimized with deep learning become more practical, their datasets inevitably contain a variety of noise, such as mislabeling and substitution by estimated inputs/outputs, which would have negative impacts on the optimization results. As a safety net, it is a natural idea to improve a stochastic gradient descent (SGD) optimizer, which updates the network parameters as the final process of learning, to be more robust to noise. The related work revealed that the first momentum utilized in the Adam-like SGD optimizers can be modified based on the noise-robust student's t-distribution, resulting in inheriting the robustness to noise. In this paper, we propose AdaTerm, which derives not only the first momentum but also all the involved statistics based on the student's t-distribution. If the computed gradients seem to probably be aberrant, AdaTerm is expected to exclude the computed gradients for updates, and reinforce the robustness for the next updates; otherwise, it updates the network parameters normally, and can relax the robustness for the next updates. With this noise-adaptive behavior, the excellent learning performance of AdaTerm was confirmed via typical optimization problems with several cases where the noise ratio would be different.