 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Axial-Attention for Lung Nodule Classification
Jan 02, 2021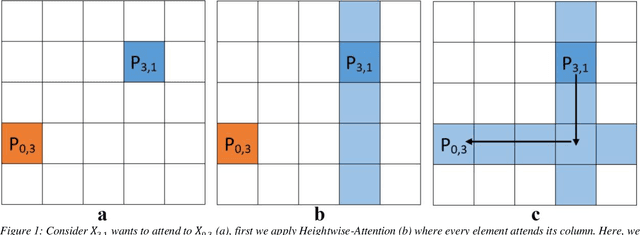

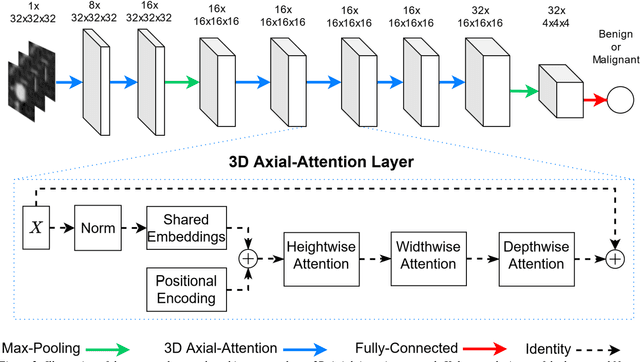
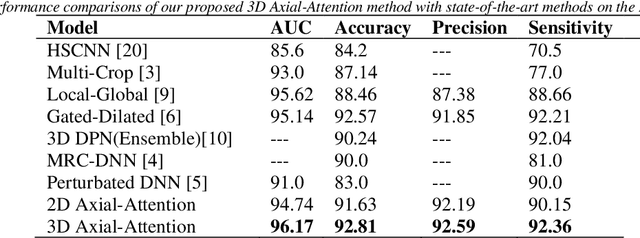
Purpose: In recent years, Non-Local based methods have been successfully applied to lung nodule classification. However, these methods offer 2D attention or a limited 3D attention to low-resolution feature maps. Moreover, they still depend on a convenient local filter such as convolution as full 3D attention is expensive to compute and requires a big dataset, which might not be available. Methods: We propose to use 3D Axial-Attention, which requires a fraction of the computing power of a regular Non-Local network. Additionally, we solve the position invariant problem of the Non-Local network by proposing adding 3D positional encoding to shared embeddings. Results: We validated the proposed method on the LIDC-IDRI dataset by following a rigorous experimental setup using only nodules annotated by at least three radiologists. Our results show that the 3D Axial-Attention model achieves state-of-the-art performance on all evaluation metrics including AUC and Accuracy. Conclusions: The proposed model provides full 3D attention effectively, which can be used in all layers without the need for local filters. The experimental results show the importance of full 3D attention for classifying lung nodules.
A new semi-supervised self-training method for lung cancer prediction
Dec 17, 2020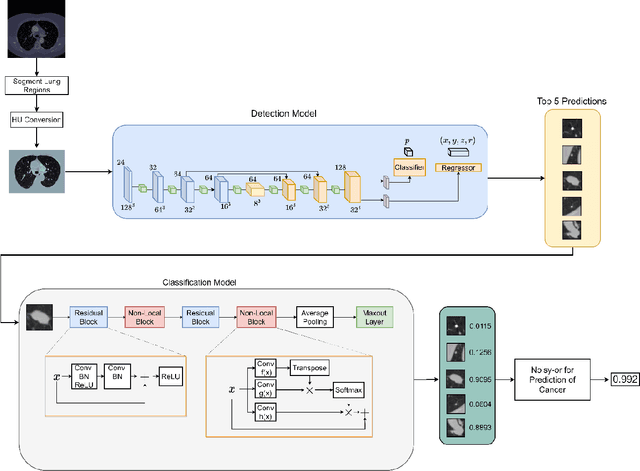

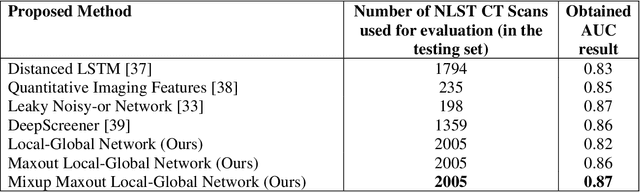
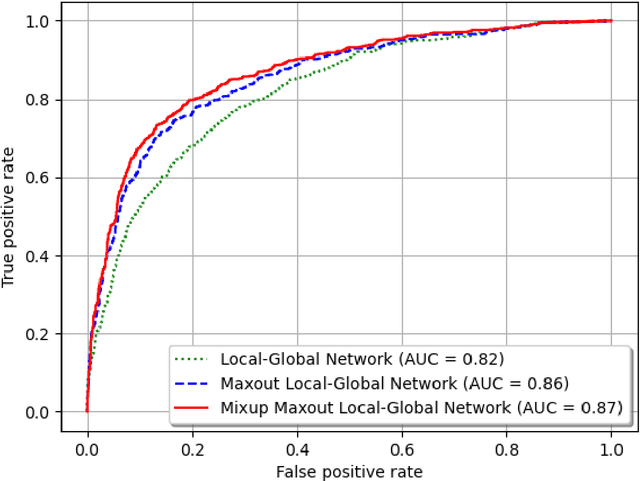
Background and Objective: Early detection of lung cancer is crucial as it has high mortality rate with patients commonly present with the disease at stage 3 and above. There are only relatively few methods that simultaneously detect and classify nodules from computed tomography (CT) scans. Furthermore, very few studies have used semi-supervised learning for lung cancer prediction. This study presents a complete end-to-end scheme to detect and classify lung nodules using the state-of-the-art Self-training with Noisy Student method on a comprehensive CT lung screening dataset of around 4,000 CT scans. Methods: We used three datasets, namely LUNA16, LIDC and NLST, for this study. We first utilise a three-dimensional deep convolutional neural network model to detect lung nodules in the detection stage. The classification model known as Maxout Local-Global Network uses non-local networks to detect global features including shape features, residual blocks to detect local features including nodule texture, and a Maxout layer to detect nodule variations. We trained the first Self-training with Noisy Student model to predict lung cancer on the unlabelled NLST datasets. Then, we performed Mixup regularization to enhance our scheme and provide robustness to erroneous labels. Results and Conclusions: Our new Mixup Maxout Local-Global network achieves an AUC of 0.87 on 2,005 completely independent testing scans from the NLST dataset. Our new scheme significantly outperformed the next highest performing method at the 5% significance level using DeLong's test (p = 0.0001). This study presents a new complete end-to-end scheme to predict lung cancer using Self-training with Noisy Student combined with Mixup regularization. On a completely independent dataset of 2,005 scans, we achieved state-of-the-art performance even with more images as compared to other methods.
ProCAN: Progressive Growing Channel Attentive Non-Local Network for Lung Nodule Classification
Nov 14, 2020



Lung cancer classification in screening computed tomography (CT) scans is one of the most crucial tasks for early detection of this disease. Many lives can be saved if we are able to accurately classify malignant/ cancerous lung nodules. Consequently, several deep learning based models have been proposed recently to classify lung nodules as malignant or benign. Nevertheless, the large variation in the size and heterogeneous appearance of the nodules makes this task an extremely challenging one. We propose a new Progressive Growing Channel Attentive Non-Local (ProCAN) network for lung nodule classification. The proposed method addresses this challenge from three different aspects. First, we enrich the Non-Local network by adding channel-wise attention capability to it. Second, we apply Curriculum Learning principles, whereby we first train our model on easy examples before hard/ difficult ones. Third, as the classification task gets harder during the Curriculum learning, our model is progressively grown to increase its capability of handling the task at hand. We examined our proposed method on two different public datasets and compared its performance with state-of-the-art methods in the literature. The results show that the ProCAN model outperforms state-of-the-art methods and achieves an AUC of 98.05% and accuracy of 95.28% on the LIDC-IDRI dataset. Moreover, we conducted extensive ablation studies to analyze the contribution and effects of each new component of our proposed method.