 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Reinforcement Learning for Predictions and Control for Limit Order Books
Oct 09, 2019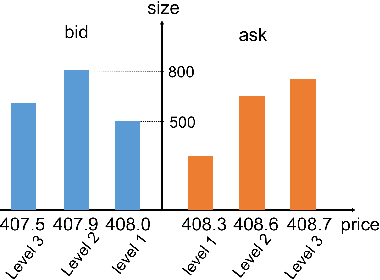
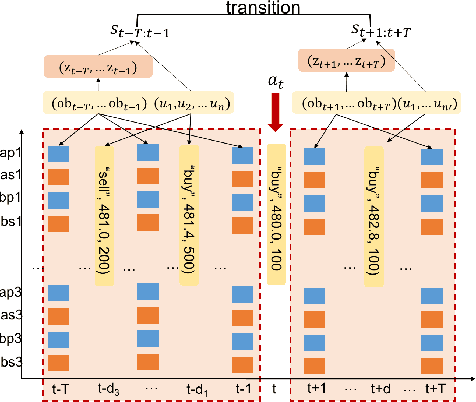
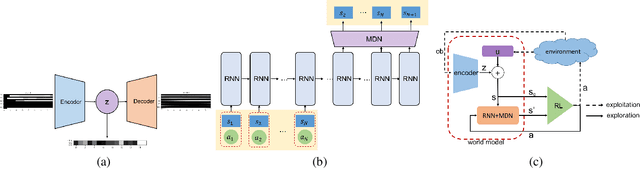
We build a profitable electronic trading agent with Reinforcement Learning that places buy and sell orders in the stock market. An environment model is built only with historical observational data, and the RL agent learns the trading policy by interacting with the environment model instead of with the real-market to minimize the risk and potential monetary loss. Trained in unsupervised and self-supervised fashion, our environment model learned a temporal and causal representation of the market in latent space through deep neural networks. We demonstrate that the trading policy trained entirely within the environment model can be transferred back into the real market and maintain its profitability. We believe that this environment model can serve as a robust simulator that predicts market movement as well as trade impact for further studies.
Decentralized Multi-Agent Actor-Critic with Generative Inference
Oct 07, 2019



Recent multi-agent actor-critic methods have utilized centralized training with decentralized execution to address the non-stationarity of co-adapting agents. This training paradigm constrains learning to the centralized phase such that only pre-learned policies may be used during the decentralized phase, which performs poorly when agent communications are delayed, noisy, or disrupted. In this work, we propose a new system that can gracefully handle partially-observable information due to communication disruptions during decentralized execution. Our approach augments the multi-agent actor-critic method's centralized training phase with generative modeling so that agents may infer other agents' observations when provided with locally available context. Our method is evaluated on three tasks that require agents to combine local and remote observations communicated by other agents. We evaluate our approach by introducing both partial observability during decentralized execution, and show that decentralized training on inferred observations performs as well or better than existing actor-critic methods.