 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACL-Fig: A Dataset for Scientific Figure Classification
Jan 28, 2023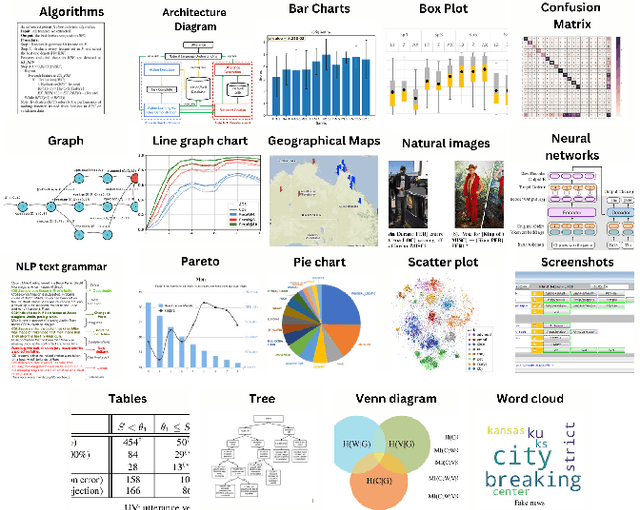
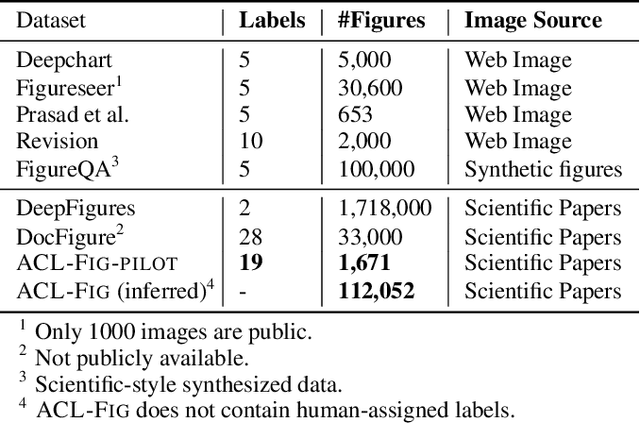
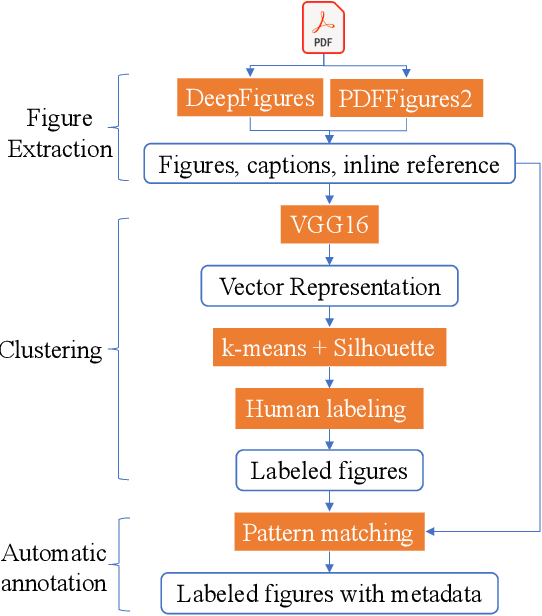

Most existing large-scale academic search engines are built to retrieve text-based information. However, there are no large-scale retrieval services for scientific figures and tables. One challenge for such services is understanding scientific figures' semantics, such as their types and purposes. A key obstacle is the need for datasets containing annotated scientific figures and tables, which can then be used for classification, question-answering, and auto-captioning. Here, we develop a pipeline that extracts figures and tables from the scientific literature and a deep-learning-based framework that classifies scientific figures using visual features. Using this pipeline, we built the first large-scale automatically annotated corpus, ACL-Fig, consisting of 112,052 scientific figures extracted from ~56K research papers in the ACL Anthology. The ACL-Fig-Pilot dataset contains 1,671 manually labeled scientific figures belonging to 19 categories. The dataset is accessible at https://huggingface.co/datasets/citeseerx/ACL-fig under a CC BY-NC license.