 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Conditioned Recommendations
Aug 05, 2019

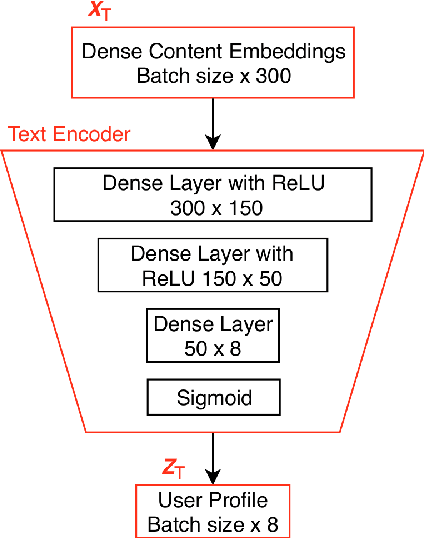
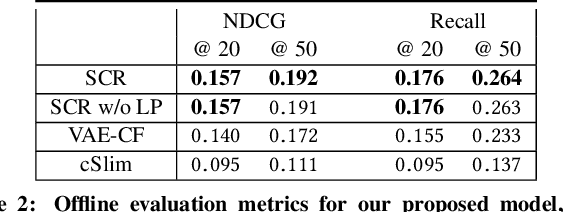
We propose Style Conditioned Recommendations (SCR) and introduce style injection as a method to diversify recommendations. We use Conditional Variational Autoencoder (CVAE) architecture, where both the encoder and decoder are conditioned on a user profile learned from item content data. This allows us to apply style transfer methodologies to the task of recommendations, which we refer to as injection. To enable style injection, user profiles are learned to be interpretable such that they express users' propensities for specific predefined styles. These are learned via label-propagation from a dataset of item content, with limited labeled points. To perform injection, the condition on the encoder is learned while the condition on the decoder is selected per explicit feedback. Explicit feedback can be taken either from a user's response to a style or interest quiz, or from item ratings. In the absence of explicit feedback, the condition at the encoder is applied to the decoder. We show a 12% improvement on NDCG@20 over the traditional VAE based approach and an average 22% improvement on AUC across all classes for predicting user style profiles against our best performing baseline. After injecting styles we compare the user style profile to the style of the recommendations and show that injected styles have an average +133% increase in presence. Our results show that style injection is a powerful method to diversify recommendations while maintaining personal relevance. Our main contribution is an application of a semi-supervised approach that extends item labels to interpretable user profiles.
Production Ranking Systems: A Review
Jul 24, 2019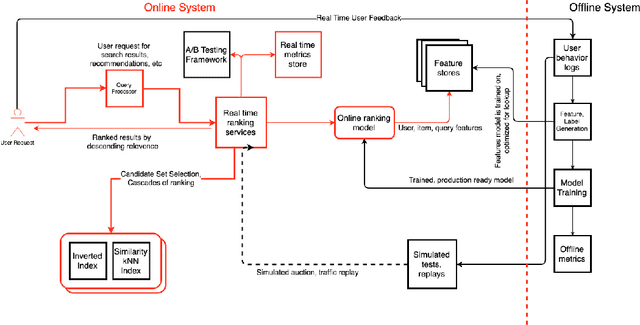
The problem of ranking is a multi-billion dollar problem. In this paper we present an overview of several production quality ranking systems. We show that due to conflicting goals of employing the most effective machine learning models and responding to users in real time, ranking systems have evolved into a system of systems, where each subsystem can be viewed as a component layer. We view these layers as being data processing, representation learning, candidate selection and online inference. Each layer employs different algorithms and tools, with every end-to-end ranking system spanning multiple architectures. Our goal is to familiarize the general audience with a working knowledge of ranking at scale, the tools and algorithms employed and the challenges introduced by adopting a layered approach.
A Multimodal Recommender System for Large-scale Assortment Generation in E-commerce
Jun 28, 2018
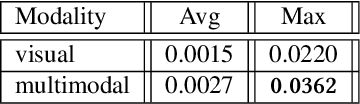
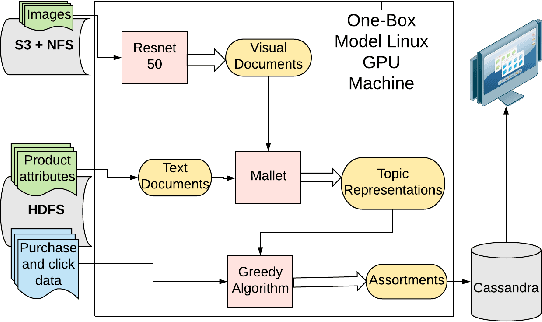

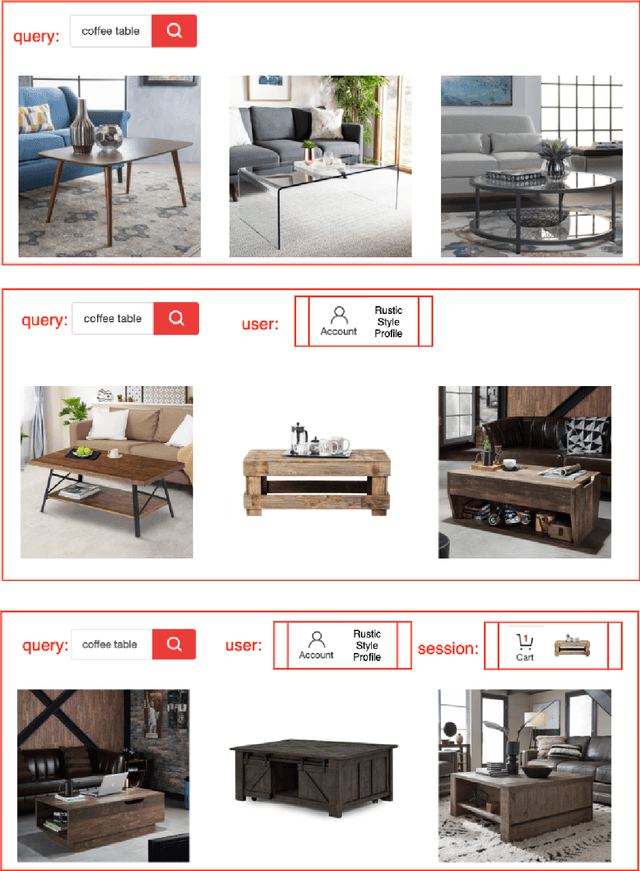
E-commerce platforms surface interesting products largely through product recommendations that capture users' styles and aesthetic preferences. Curating recommendations as a complete complementary set, or assortment, is critical for a successful e-commerce experience, especially for product categories such as furniture, where items are selected together with the overall theme, style or ambiance of a space in mind. In this paper, we propose two visually-aware recommender systems that can automatically curate an assortment of living room furniture around a couple of pre-selected seed pieces for the room. The first system aims to maximize the visual-based style compatibility of the entire selection by making use of transfer learning and topic modeling. The second system extends the first by incorporating text data and applying polylingual topic modeling to infer style over both modalities. We review the production pipeline for surfacing these visually-aware recommender systems and compare them through offline validations and large-scale online A/B tests on Overstock. Our experimental results show that complimentary style is best discovered over product sets when both visual and textual data are incorporated.
Discovering Style Trends through Deep Visually Aware Latent Item Embeddings
Apr 23, 2018


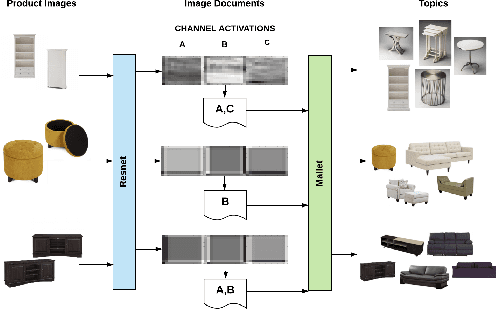
In this paper, we explore Latent Dirichlet Allocation (LDA) and Polylingual Latent Dirichlet Allocation (PolyLDA), as a means to discover trending styles in Overstock from deep visual semantic features transferred from a pretrained convolutional neural network and text-based item attributes. To utilize deep visual semantic features in conjunction with LDA, we develop a method for creating a bag of words representation of unrolled image vectors. By viewing the channels within the convolutional layers of a Resnet-50 as being representative of a word, we can index these activations to create visual documents. We then train LDA over these documents to discover the latent style in the images. We also incorporate text-based data with PolyLDA, where each representation is viewed as an independent language attempting to describe the same style. The resulting topics are shown to be excellent indicators of visual style across our platform.
Neural Networks with Manifold Learning for Diabetic Retinopathy Detection
Dec 12, 2016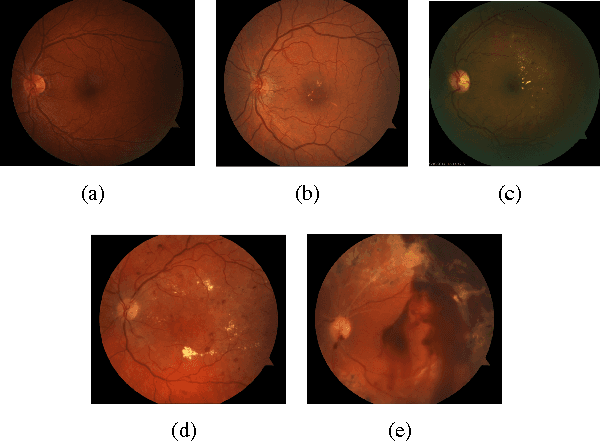
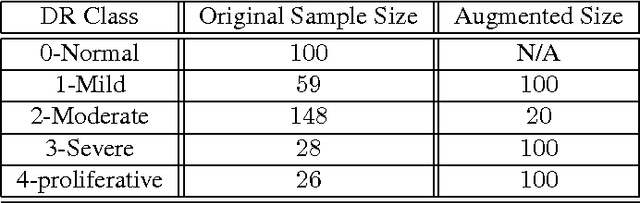

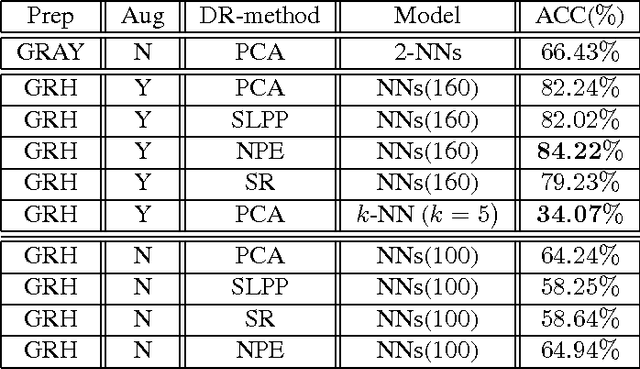
Widespread outreach programs using remote retinal imaging have proven to decrease the risk from diabetic retinopathy, the leading cause of blindness in the US. However, this process still requires manual verification of image quality and grading of images for level of disease by a trained human grader and will continue to be limited by the lack of such scarce resources. Computer-aided diagnosis of retinal images have recently gained increasing attention in the machine learning community. In this paper, we introduce a set of neural networks for diabetic retinopathy classification of fundus retinal images. We evaluate the efficiency of the proposed classifiers in combination with preprocessing and augmentation steps on a sample dataset. Our experimental results show that neural networks in combination with preprocessing on the images can boost the classification accuracy on this dataset. Moreover the proposed models are scalable and can be used in large scale datasets for diabetic retinopathy detection. The models introduced in this paper can be used to facilitate the diagnosis and speed up the detection process.
Item Popularity Prediction in E-commerce Using Image Quality Feature Vectors
May 12, 2016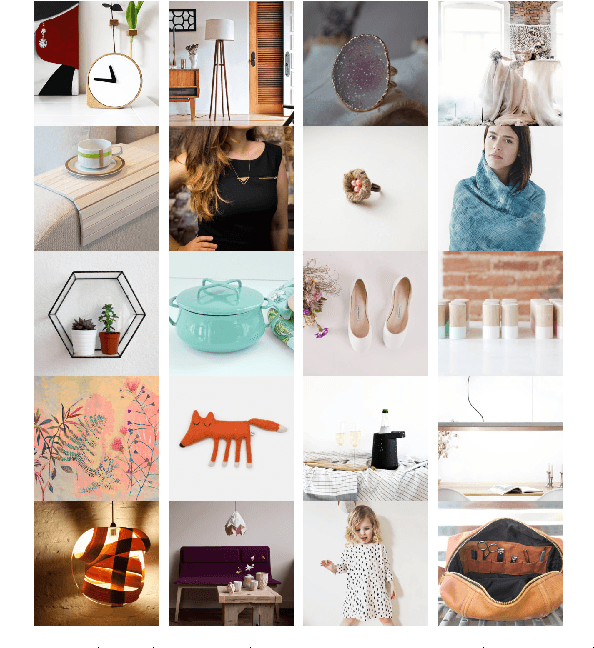



Online retail is a visual experience- Shoppers often use images as first order information to decide if an item matches their personal style. Image characteristics such as color, simplicity, scene composition, texture, style, aesthetics and overall quality play a crucial role in making a purchase decision, clicking on or liking a product listing. In this paper we use a set of image features that indicate quality to predict product listing popularity on a major e-commerce website, Etsy. We first define listing popularity through search clicks, favoriting and purchase activity. Next, we infer listing quality from the pixel-level information of listed images as quality features. We then compare our findings to text-only models for popularity prediction. Our initial results indicate that a combined image and text modeling of product listings outperforms text-only models in popularity prediction.
Road Detection through Supervised Classification
May 10, 2016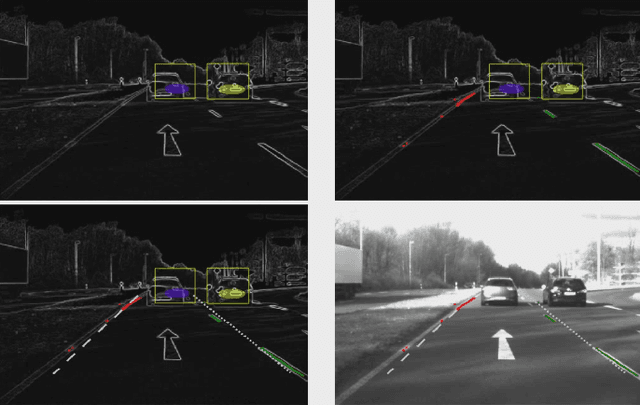



Autonomous driving is a rapidly evolving technology. Autonomous vehicles are capable of sensing their environment and navigating without human input through sensory information such as radar, lidar, GNSS, vehicle odometry, and computer vision. This sensory input provides a rich dataset that can be used in combination with machine learning models to tackle multiple problems in supervised settings. In this paper we focus on road detection through gray-scale images as the sole sensory input. Our contributions are twofold: first, we introduce an annotated dataset of urban roads for machine learning tasks; second, we introduce a road detection framework on this dataset through supervised classification and hand-crafted feature vectors.
Images Don't Lie: Transferring Deep Visual Semantic Features to Large-Scale Multimodal Learning to Rank
Nov 20, 2015

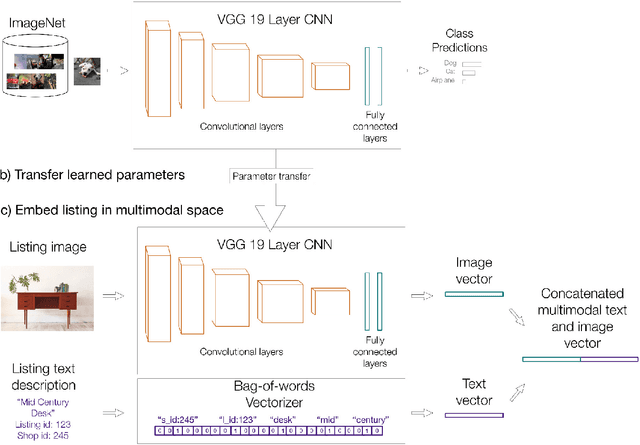

Search is at the heart of modern e-commerce. As a result, the task of ranking search results automatically (learning to rank) is a multibillion dollar machine learning problem. Traditional models optimize over a few hand-constructed features based on the item's text. In this paper, we introduce a multimodal learning to rank model that combines these traditional features with visual semantic features transferred from a deep convolutional neural network. In a large scale experiment using data from the online marketplace Etsy, we verify that moving to a multimodal representation significantly improves ranking quality. We show how image features can capture fine-grained style information not available in a text-only representation. In addition, we show concrete examples of how image information can successfully disentangle pairs of highly different items that are ranked similarly by a text-only model.