 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Is Better Than One: Dual Embeddings for Complementary Product Recommendations
Nov 29, 2022Embedding based product recommendations have gained popularity in recent years due to its ability to easily integrate to large-scale systems and allowing nearest neighbor searches in real-time. The bulk of studies in this area has predominantly been focused on similar item recommendations. Research on complementary item recommendations, on the other hand, still remains considerably under-explored. We define similar items as items that are interchangeable in terms of their utility and complementary items as items that serve different purposes, yet are compatible when used with one another. In this paper, we apply a novel approach to finding complementary items by leveraging dual embedding representations for products. We demonstrate that the notion of relatedness discovered in NLP for skip-gram negative sampling (SGNS) models translates effectively to the concept of complementarity when training item representations using co-purchase data. Since sparsity of purchase data is a major challenge in real-world scenarios, we further augment the model using synthetic samples to extend coverage. This allows the model to provide complementary recommendations for items that do not share co-purchase data by leveraging other abundantly available data modalities such as images, text, clicks etc. We establish the effectiveness of our approach in improving both coverage and quality of recommendations on real world data for a major online retail company. We further show the importance of task specific hyperparameter tuning in training SGNS. Our model is effective yet simple to implement, making it a great candidate for generating complementary item recommendations at any e-commerce website.
Production Ranking Systems: A Review
Jul 24, 2019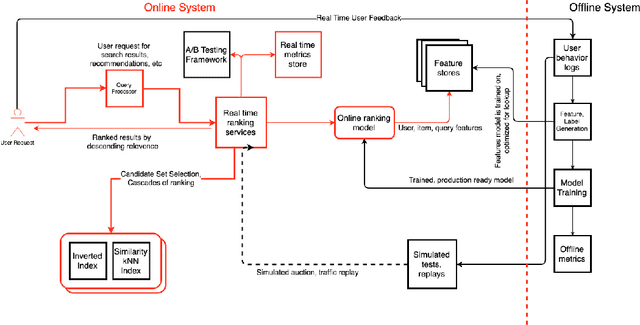
The problem of ranking is a multi-billion dollar problem. In this paper we present an overview of several production quality ranking systems. We show that due to conflicting goals of employing the most effective machine learning models and responding to users in real time, ranking systems have evolved into a system of systems, where each subsystem can be viewed as a component layer. We view these layers as being data processing, representation learning, candidate selection and online inference. Each layer employs different algorithms and tools, with every end-to-end ranking system spanning multiple architectures. Our goal is to familiarize the general audience with a working knowledge of ranking at scale, the tools and algorithms employed and the challenges introduced by adopting a layered approach.