 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Boundaries: Learning a Universal Entity Taxonomy across Datasets and Languages for Open Named Entity Recognition
Jun 17, 2024
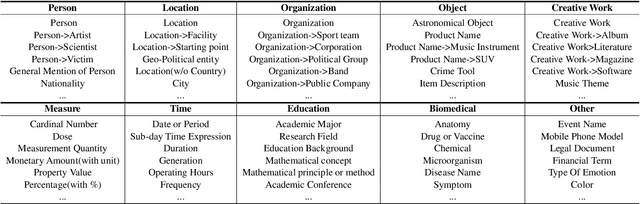
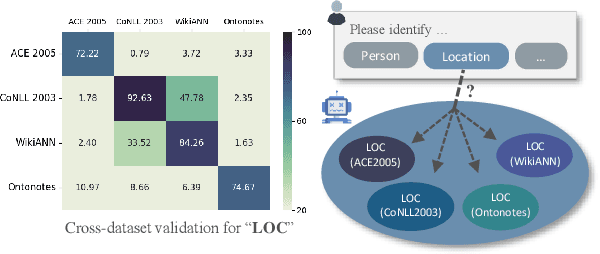
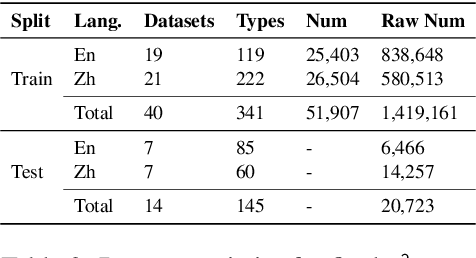
Open Named Entity Recognition (NER), which involves identifying arbitrary types of entities from arbitrary domains, remains challenging for Large Language Models (LLMs). Recent studies suggest that fine-tuning LLMs on extensive NER data can boost their performance. However, training directly on existing datasets faces issues due to inconsistent entity definitions and redundant data, limiting LLMs to dataset-specific learning and hindering out-of-domain generalization. To address this, we present B2NERD, a cohesive and efficient dataset for Open NER, normalized from 54 existing English or Chinese datasets using a two-step approach. First, we detect inconsistent entity definitions across datasets and clarify them by distinguishable label names to construct a universal taxonomy of 400+ entity types. Second, we address redundancy using a data pruning strategy that selects fewer samples with greater category and semantic diversity. Comprehensive evaluation shows that B2NERD significantly improves LLMs' generalization on Open NER. Our B2NER models, trained on B2NERD, outperform GPT-4 by 6.8-12.0 F1 points and surpass previous methods in 3 out-of-domain benchmarks across 15 datasets and 6 languages.
Solving Continual Offline Reinforcement Learning with Decision Transformer
Jan 16, 2024



Continuous offline reinforcement learning (CORL) combines continuous and offline reinforcement learning, enabling agents to learn multiple tasks from static datasets without forgetting prior tasks. However, CORL faces challenges in balancing stability and plasticity. Existing methods, employing Actor-Critic structures and experience replay (ER), suffer from distribution shifts, low efficiency, and weak knowledge-sharing. We aim to investigate whether Decision Transformer (DT), another offline RL paradigm, can serve as a more suitable offline continuous learner to address these issues. We first compare AC-based offline algorithms with DT in the CORL framework. DT offers advantages in learning efficiency, distribution shift mitigation, and zero-shot generalization but exacerbates the forgetting problem during supervised parameter updates. We introduce multi-head DT (MH-DT) and low-rank adaptation DT (LoRA-DT) to mitigate DT's forgetting problem. MH-DT stores task-specific knowledge using multiple heads, facilitating knowledge sharing with common components. It employs distillation and selective rehearsal to enhance current task learning when a replay buffer is available. In buffer-unavailable scenarios, LoRA-DT merges less influential weights and fine-tunes DT's decisive MLP layer to adapt to the current task. Extensive experiments on MoJuCo and Meta-World benchmarks demonstrate that our methods outperform SOTA CORL baselines and showcase enhanced learning capabilities and superior memory efficiency.