 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGI-SMN: Gradient Inversion Attack against Federated Learning without Prior Knowledge
May 06, 2024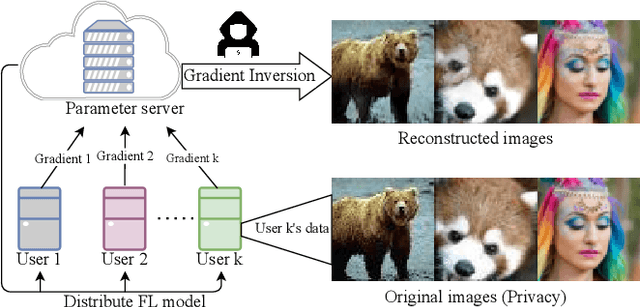
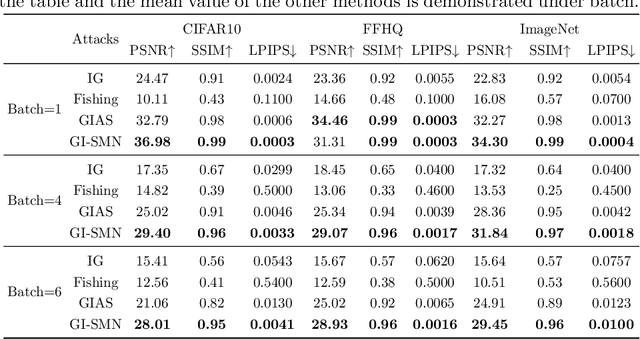
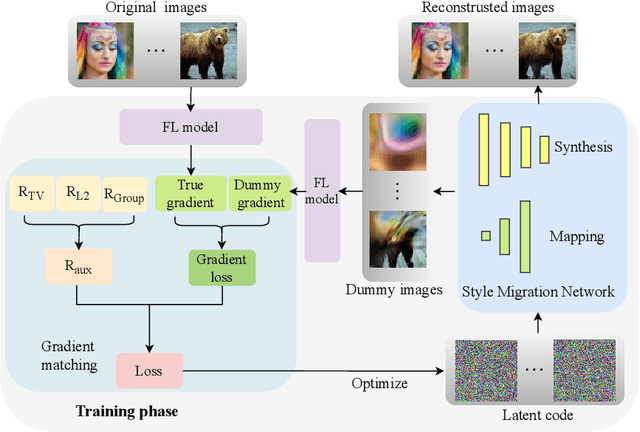
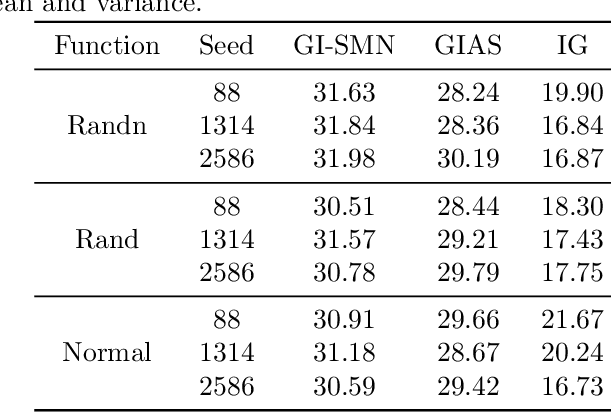
Federated learning (FL) has emerged as a privacy-preserving machine learning approach where multiple parties share gradient information rather than original user data. Recent work has demonstrated that gradient inversion attacks can exploit the gradients of FL to recreate the original user data, posing significant privacy risks. However, these attacks make strong assumptions about the attacker, such as altering the model structure or parameters, gaining batch normalization statistics, or acquiring prior knowledge of the original training set, etc. Consequently, these attacks are not possible in real-world scenarios. To end it, we propose a novel Gradient Inversion attack based on Style Migration Network (GI-SMN), which breaks through the strong assumptions made by previous gradient inversion attacks. The optimization space is reduced by the refinement of the latent code and the use of regular terms to facilitate gradient matching. GI-SMN enables the reconstruction of user data with high similarity in batches. Experimental results have demonstrated that GI-SMN outperforms state-of-the-art gradient inversion attacks in both visual effect and similarity metrics. Additionally, it also can overcome gradient pruning and differential privacy defenses.
Distributional Black-Box Model Inversion Attack with Multi-Agent Reinforcement Learning
Apr 22, 2024A Model Inversion (MI) attack based on Generative Adversarial Networks (GAN) aims to recover the private training data from complex deep learning models by searching codes in the latent space. However, they merely search a deterministic latent space such that the found latent code is usually suboptimal. In addition, the existing distributional MI schemes assume that an attacker can access the structures and parameters of the target model, which is not always viable in practice. To overcome the above shortcomings, this paper proposes a novel Distributional Black-Box Model Inversion (DBB-MI) attack by constructing the probabilistic latent space for searching the target privacy data. Specifically, DBB-MI does not need the target model parameters or specialized GAN training. Instead, it finds the latent probability distribution by combining the output of the target model with multi-agent reinforcement learning techniques. Then, it randomly chooses latent codes from the latent probability distribution for recovering the private data. As the latent probability distribution closely aligns with the target privacy data in latent space, the recovered data will leak the privacy of training samples of the target model significantly. Abundant experiments conducted on diverse datasets and networks show that the present DBB-MI has better performance than state-of-the-art in attack accuracy, K-nearest neighbor feature distance, and Peak Signal-to-Noise Ratio.
Session-based Recommendation with Heterogeneous Graph Neural Network
Aug 12, 2021



The purpose of the Session-Based Recommendation System is to predict the user's next click according to the previous session sequence. The current studies generally learn user preferences according to the transitions of items in the user's session sequence. However, other effective information in the session sequence, such as user profiles, are largely ignored which may lead to the model unable to learn the user's specific preferences. In this paper, we propose a heterogeneous graph neural network-based session recommendation method, named SR-HetGNN, which can learn session embeddings by heterogeneous graph neural network (HetGNN), and capture the specific preferences of anonymous users. Specifically, SR-HetGNN first constructs heterogeneous graphs containing various types of nodes according to the session sequence, which can capture the dependencies among items, users, and sessions. Second, HetGNN captures the complex transitions between items and learns the item embeddings containing user information. Finally, to consider the influence of users' long and short-term preferences, local and global session embeddings are combined with the attentional network to obtain the final session embedding. SR-HetGNN is shown to be superior to the existing state-of-the-art session-based recommendation methods through extensive experiments over two real large datasets Diginetica and Tmall.