 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-Accelerated Viterbi Exact Lattice Decoder for Batched Online and Offline Speech Recognition
Oct 22, 2019
We present an optimized weighted finite-state transducer (WFST) decoder capable of online streaming and offline batch processing of audio using Graphics Processing Units (GPUs). The decoder is efficient in memory utilization, input/output bandwidth, and uses a novel Viterbi implementation designed to maximize parallelism. Memory savings enable the decoder to process larger graphs than previously possible while simultaneously supporting larger numbers of consecutive streams. GPU preprocessing of lattice segments enable intermediate lattice results to be returned to the requestor during streaming inference. Collectively, the proposed improvements achieve up to a 240x speedup over single core CPU decoding, and up to 40x faster decoding than the current state-of-the-art GPU decoder, while returning equivalent results. This architecture also makes deployment of production-grade models on hardware ranging from large data center servers to low-power edge devices practical.
A GPU-based WFST Decoder with Exact Lattice Generation
Jul 27, 2018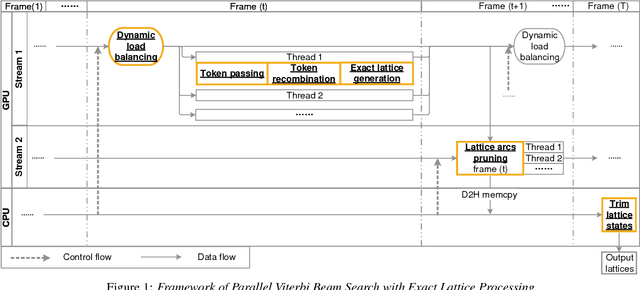

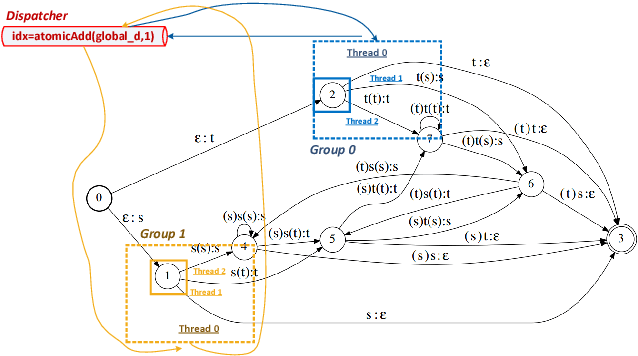
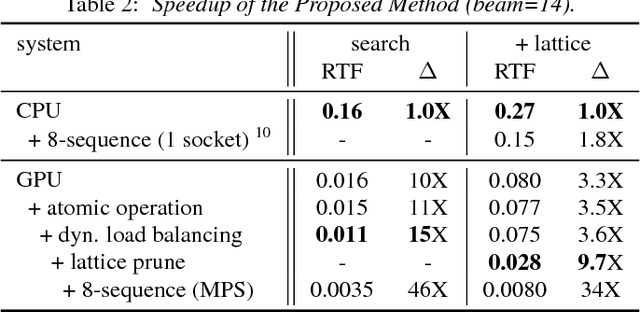
We describe initial work on an extension of the Kaldi toolkit that supports weighted finite-state transducer (WFST) decoding on Graphics Processing Units (GPUs). We implement token recombination as an atomic GPU operation in order to fully parallelize the Viterbi beam search, and propose a dynamic load balancing strategy for more efficient token passing scheduling among GPU threads. We also redesign the exact lattice generation and lattice pruning algorithms for better utilization of the GPUs. Experiments on the Switchboard corpus show that the proposed method achieves identical 1-best results and lattice quality in recognition and confidence measure tasks, while running 3 to 15 times faster than the single process Kaldi decoder. The above results are reported on different GPU architectures. Additionally we obtain a 46-fold speedup with sequence parallelism and multi-process service (MPS) in GPU.