 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-Accelerated Viterbi Exact Lattice Decoder for Batched Online and Offline Speech Recognition
Paper and Code
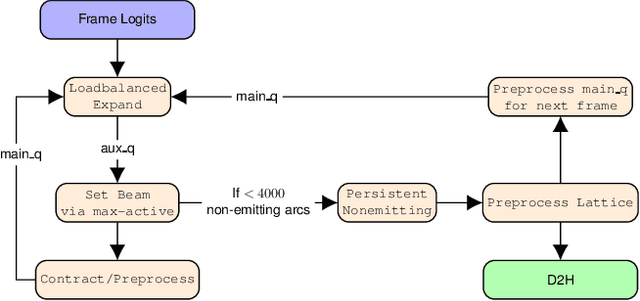
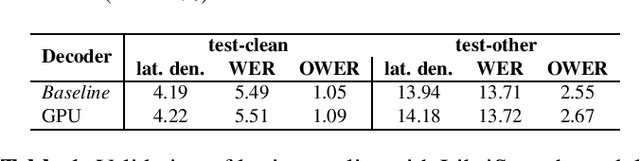
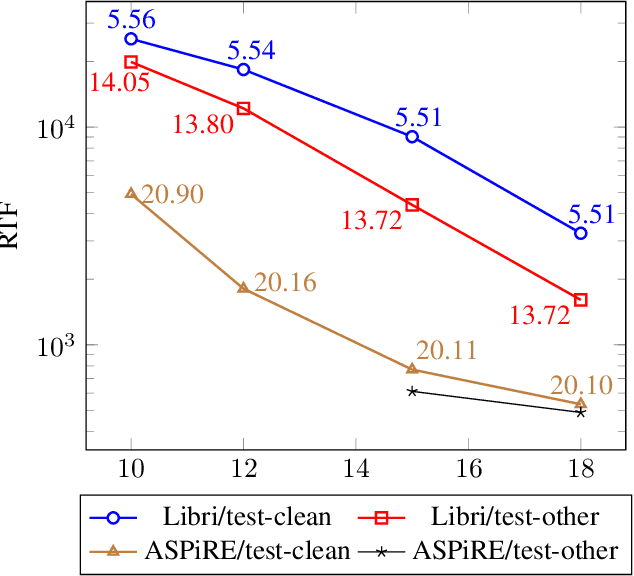
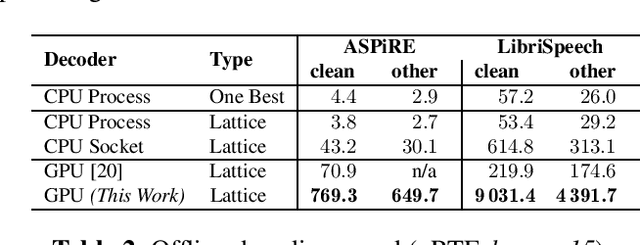
We present an optimized weighted finite-state transducer (WFST) decoder capable of online streaming and offline batch processing of audio using Graphics Processing Units (GPUs). The decoder is efficient in memory utilization, input/output bandwidth, and uses a novel Viterbi implementation designed to maximize parallelism. Memory savings enable the decoder to process larger graphs than previously possible while simultaneously supporting larger numbers of consecutive streams. GPU preprocessing of lattice segments enable intermediate lattice results to be returned to the requestor during streaming inference. Collectively, the proposed improvements achieve up to a 240x speedup over single core CPU decoding, and up to 40x faster decoding than the current state-of-the-art GPU decoder, while returning equivalent results. This architecture also makes deployment of production-grade models on hardware ranging from large data center servers to low-power edge devices practical.