 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Chinese Chess AI (Xiangqi) Without Search
Oct 07, 2024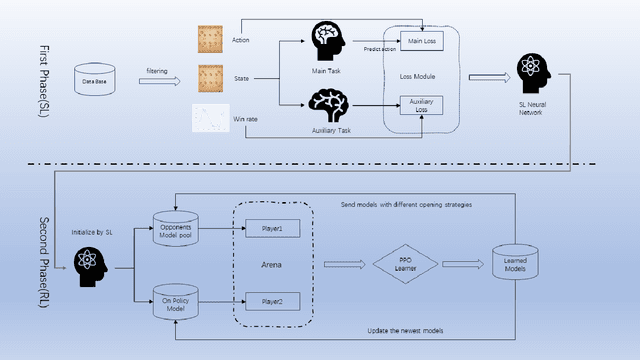

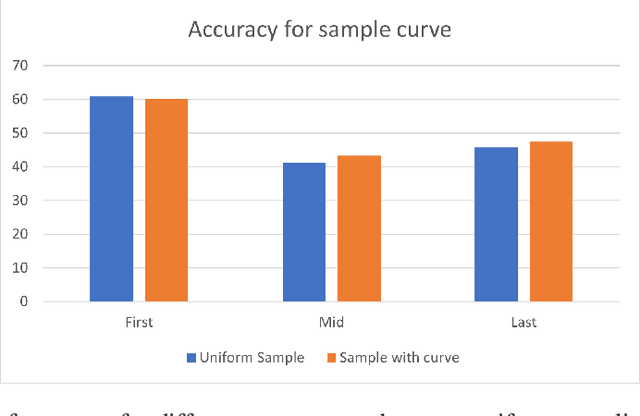
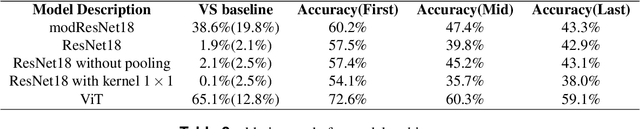
We have developed a high-performance Chinese Chess AI that operates without reliance on search algorithms. This AI has demonstrated the capability to compete at a level commensurate with the top 0.1\% of human players. By eliminating the search process typically associated with such systems, this AI achieves a Queries Per Second (QPS) rate that exceeds those of systems based on the Monte Carlo Tree Search (MCTS) algorithm by over a thousandfold and surpasses those based on the AlphaBeta pruning algorithm by more than a hundredfold. The AI training system consists of two parts: supervised learning and reinforcement learning. Supervised learning provides an initial human-like Chinese chess AI, while reinforcement learning, based on supervised learning, elevates the strength of the entire AI to a new level. Based on this training system, we carried out enough ablation experiments and discovered that 1. The same parameter amount of Transformer architecture has a higher performance than CNN on Chinese chess; 2. Possible moves of both sides as features can greatly improve the training process; 3. Selective opponent pool, compared to pure self-play training, results in a faster improvement curve and a higher strength limit. 4. Value Estimation with Cutoff(VECT) improves the original PPO algorithm training process and we will give the explanation.
End-to-end Decentralized Multi-robot Navigation in Unknown Complex Environments via Deep Reinforcement Learning
Jul 03, 2019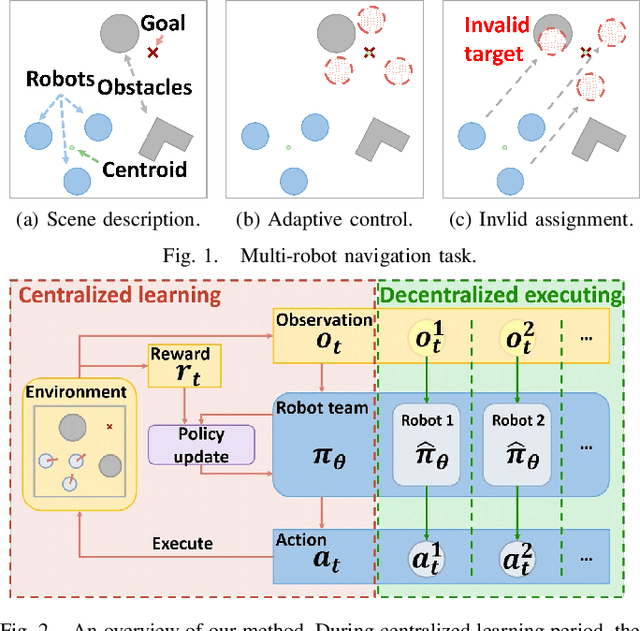
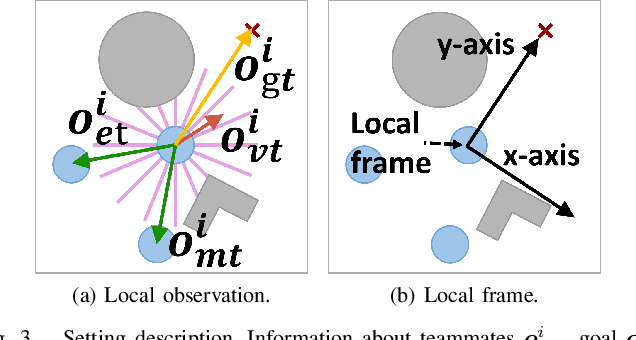
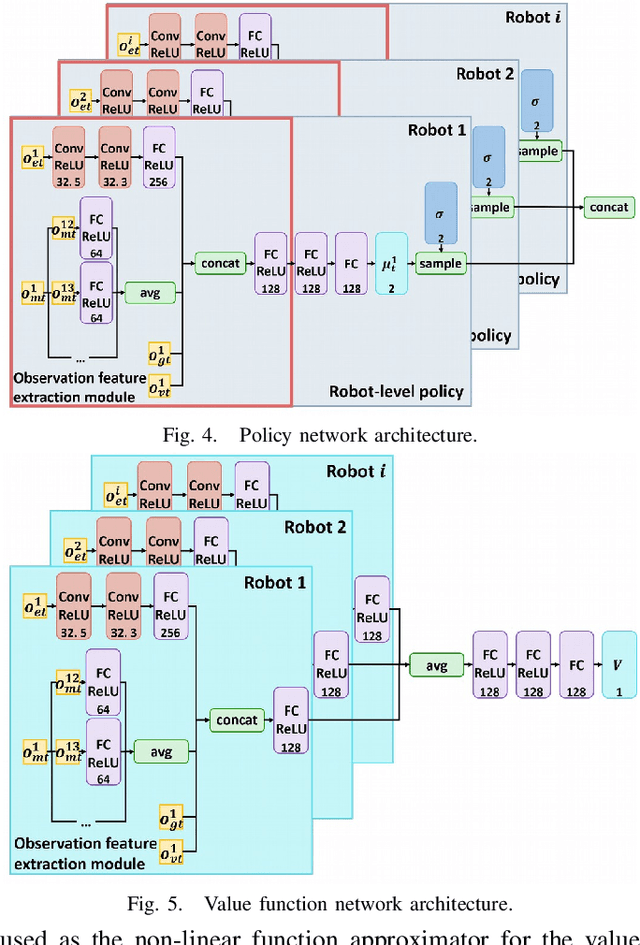
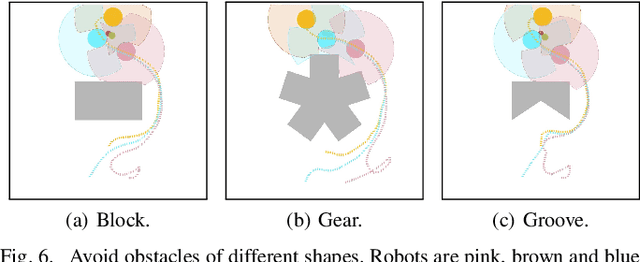
In this paper, a novel deep reinforcement learning (DRL)-based method is proposed to navigate the robot team through unknown complex environments, where the geometric centroid of the robot team aims to reach the goal position while avoiding collisions and maintaining connectivity. Decentralized robot-level policies are derived using a mechanism of centralized learning and decentralized executing. The proposed method can derive end-to-end policies, which map raw lidar measurements into velocity control commands of robots without the necessity of constructing obstacle maps. Simulation and indoor real-world unmanned ground vehicles (UGVs) experimental results verify the effectiveness of the proposed method.