Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Decentralized Multi-robot Navigation in Unknown Complex Environments via Deep Reinforcement Learning
Paper and Code
Jul 03, 2019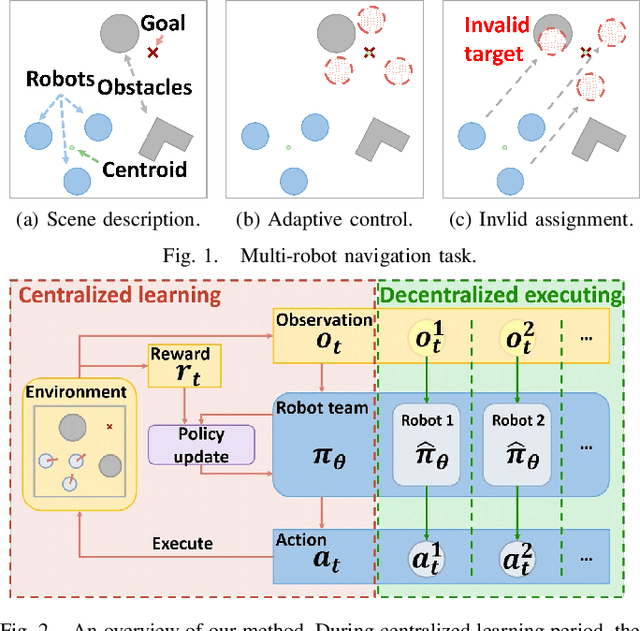
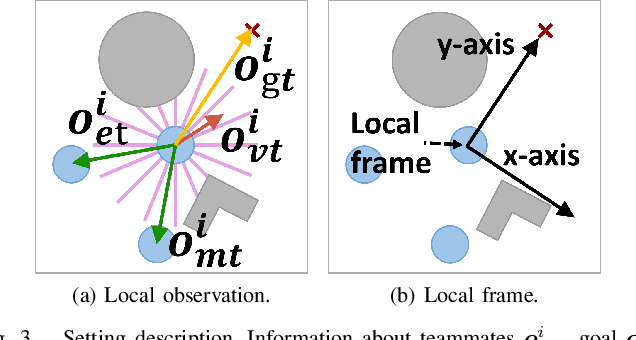
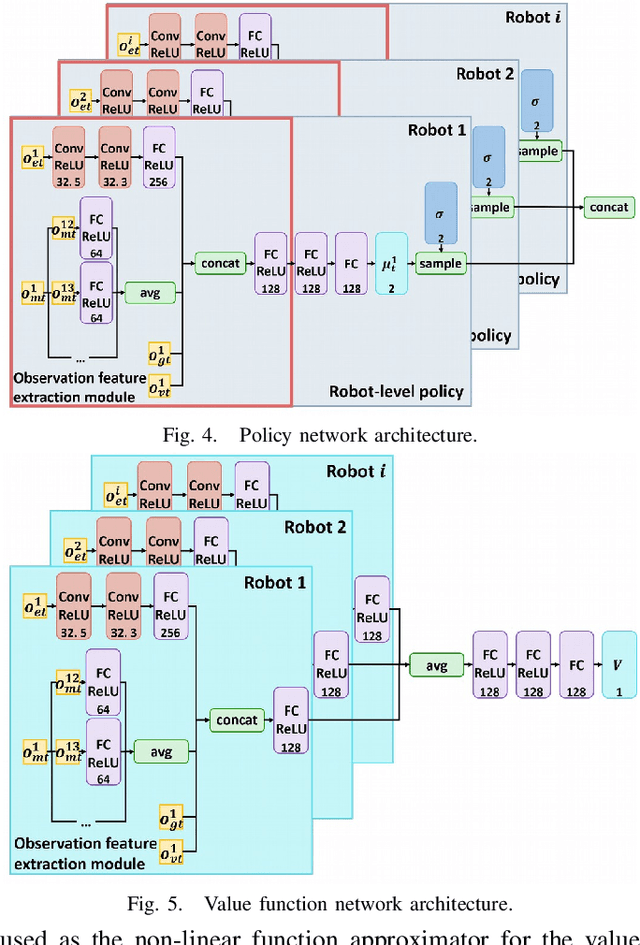
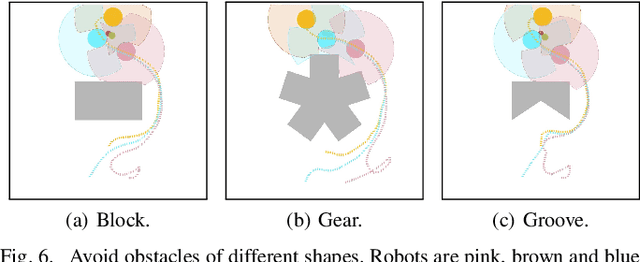
In this paper, a novel deep reinforcement learning (DRL)-based method is proposed to navigate the robot team through unknown complex environments, where the geometric centroid of the robot team aims to reach the goal position while avoiding collisions and maintaining connectivity. Decentralized robot-level policies are derived using a mechanism of centralized learning and decentralized executing. The proposed method can derive end-to-end policies, which map raw lidar measurements into velocity control commands of robots without the necessity of constructing obstacle maps. Simulation and indoor real-world unmanned ground vehicles (UGVs) experimental results verify the effectiveness of the proposed method.
* 8 pages, 13 figures, IEEE International Conference on Mechatronics
and Automation (ICMA 2019)
View paper on