 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-IC: Aligned Diffusion Transformer for Efficient Image Compression
Mar 13, 2026Diffusion-based image compression has recently shown outstanding perceptual fidelity, yet its practicality is hindered by prohibitive sampling overhead and high memory usage. Most existing diffusion codecs employ U-Net architectures, where hierarchical downsampling forces diffusion to operate in shallow latent spaces (typically with only 8x spatial downscaling), resulting in excessive computation. In contrast, conventional VAE-based codecs work in much deeper latent domains (16x - 64x downscaled), motivating a key question: Can diffusion operate effectively in such compact latent spaces without compromising reconstruction quality? To address this, we introduce DiT-IC, an Aligned Diffusion Transformer for Image Compression, which replaces the U-Net with a Diffusion Transformer capable of performing diffusion in latent space entirely at 32x downscaled resolution. DiT-IC adapts a pretrained text-to-image multi-step DiT into a single-step reconstruction model through three key alignment mechanisms: (1) a variance-guided reconstruction flow that adapts denoising strength to latent uncertainty for efficient reconstruction; (2) a self-distillation alignment that enforces consistency with encoder-defined latent geometry to enable one-step diffusion; and (3) a latent-conditioned guidance that replaces text prompts with semantically aligned latent conditions, enabling text-free inference. With these designs, DiT-IC achieves state-of-the-art perceptual quality while offering up to 30x faster decoding and drastically lower memory usage than existing diffusion-based codecs. Remarkably, it can reconstruct 2048x2048 images on a 16 GB laptop GPU.
Reinforced Rate Control for Neural Video Compression via Inter-Frame Rate-Distortion Awareness
Jan 27, 2026Neural video compression (NVC) has demonstrated superior compression efficiency, yet effective rate control remains a significant challenge due to complex temporal dependencies. Existing rate control schemes typically leverage frame content to capture distortion interactions, overlooking inter-frame rate dependencies arising from shifts in per-frame coding parameters. This often leads to suboptimal bitrate allocation and cascading parameter decisions. To address this, we propose a reinforcement-learning (RL)-based rate control framework that formulates the task as a frame-by-frame sequential decision process. At each frame, an RL agent observes a spatiotemporal state and selects coding parameters to optimize a long-term reward that reflects rate-distortion (R-D) performance and bitrate adherence. Unlike prior methods, our approach jointly determines bitrate allocation and coding parameters in a single step, independent of group of pictures (GOP) structure. Extensive experiments across diverse NVC architectures show that our method reduces the average relative bitrate error to 1.20% and achieves up to 13.45% bitrate savings at typical GOP sizes, outperforming existing approaches. In addition, our framework demonstrates improved robustness to content variation and bandwidth fluctuations with lower coding overhead, making it highly suitable for practical deployment.
YODA: Yet Another One-step Diffusion-based Video Compressor
Jan 03, 2026While one-step diffusion models have recently excelled in perceptual image compression, their application to video remains limited. Prior efforts typically rely on pretrained 2D autoencoders that generate per-frame latent representations independently, thereby neglecting temporal dependencies. We present YODA--Yet Another One-step Diffusion-based Video Compressor--which embeds multiscale features from temporal references for both latent generation and latent coding to better exploit spatial-temporal correlations for more compact representation, and employs a linear Diffusion Transformer (DiT) for efficient one-step denoising. YODA achieves state-of-the-art perceptual performance, consistently outperforming traditional and deep-learning baselines on LPIPS, DISTS, FID, and KID. Source code will be publicly available at https://github.com/NJUVISION/YODA.
On Quantizing Neural Representation for Variable-Rate Video Coding
Feb 17, 2025This work introduces NeuroQuant, a novel post-training quantization (PTQ) approach tailored to non-generalized Implicit Neural Representations for variable-rate Video Coding (INR-VC). Unlike existing methods that require extensive weight retraining for each target bitrate, we hypothesize that variable-rate coding can be achieved by adjusting quantization parameters (QPs) of pre-trained weights. Our study reveals that traditional quantization methods, which assume inter-layer independence, are ineffective for non-generalized INR-VC models due to significant dependencies across layers. To address this, we redefine variable-rate INR-VC as a mixed-precision quantization problem and establish a theoretical framework for sensitivity criteria aimed at simplified, fine-grained rate control. Additionally, we propose network-wise calibration and channel-wise quantization strategies to minimize quantization-induced errors, arriving at a unified formula for representation-oriented PTQ calibration. Our experimental evaluations demonstrate that NeuroQuant significantly outperforms existing techniques in varying bitwidth quantization and compression efficiency, accelerating encoding by up to eight times and enabling quantization down to INT2 with minimal reconstruction loss. This work introduces variable-rate INR-VC for the first time and lays a theoretical foundation for future research in rate-distortion optimization, advancing the field of video coding technology. The materials will be available at https://github.com/Eric-qi/NeuroQuant.
HINER: Neural Representation for Hyperspectral Image
Jul 31, 2024
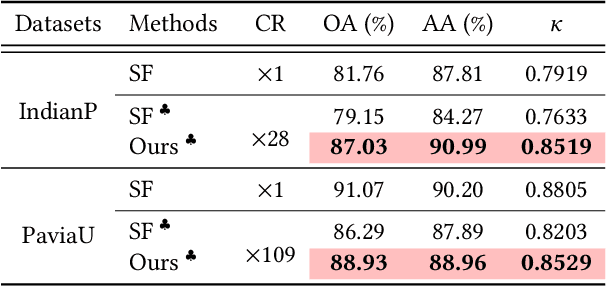
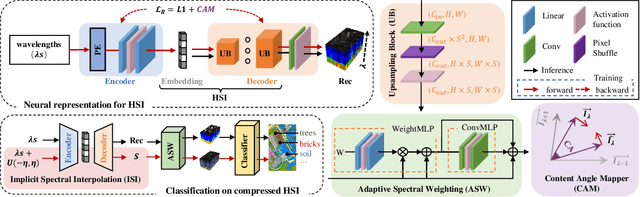
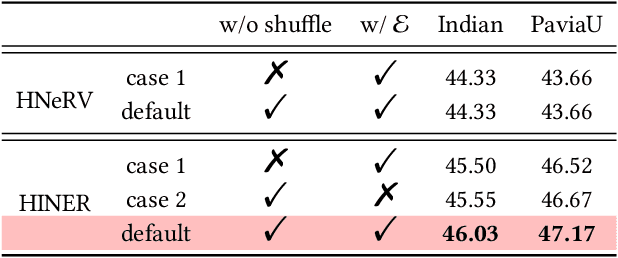
This paper introduces {HINER}, a novel neural representation for compressing HSI and ensuring high-quality downstream tasks on compressed HSI. HINER fully exploits inter-spectral correlations by explicitly encoding of spectral wavelengths and achieves a compact representation of the input HSI sample through joint optimization with a learnable decoder. By additionally incorporating the Content Angle Mapper with the L1 loss, we can supervise the global and local information within each spectral band, thereby enhancing the overall reconstruction quality. For downstream classification on compressed HSI, we theoretically demonstrate the task accuracy is not only related to the classification loss but also to the reconstruction fidelity through a first-order expansion of the accuracy degradation, and accordingly adapt the reconstruction by introducing Adaptive Spectral Weighting. Owing to the monotonic mapping of HINER between wavelengths and spectral bands, we propose Implicit Spectral Interpolation for data augmentation by adding random variables to input wavelengths during classification model training. Experimental results on various HSI datasets demonstrate the superior compression performance of our HINER compared to the existing learned methods and also the traditional codecs. Our model is lightweight and computationally efficient, which maintains high accuracy for downstream classification task even on decoded HSIs at high compression ratios. Our materials will be released at https://github.com/Eric-qi/HINER.
Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression
Nov 05, 2022Quantizing floating-point neural network to its fixed-point representation is crucial for Learned Image Compression (LIC) because it ensures the decoding consistency for interoperability and reduces space-time complexity for implementation. Existing solutions often have to retrain the network for model quantization which is time consuming and impractical. This work suggests the use of Post-Training Quantization (PTQ) to directly process pretrained, off-the-shelf LIC models. We theoretically prove that minimizing the mean squared error (MSE) in PTQ is sub-optimal for compression task and thus develop a novel Rate-Distortion (R-D) Optimized PTQ (RDO-PTQ) to best retain the compression performance. Such RDO-PTQ just needs to compress few images (e.g., 10) to optimize the transformation of weight, bias, and activation of underlying LIC model from its native 32-bit floating-point (FP32) format to 8-bit fixed-point (INT8) precision for fixed-point inference onwards. Experiments reveal outstanding efficiency of the proposed method on different LICs, showing the closest coding performance to their floating-point counterparts. And, our method is a lightweight and plug-and-play approach without any need of model retraining which is attractive to practitioners.