 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization
Jun 02, 2018

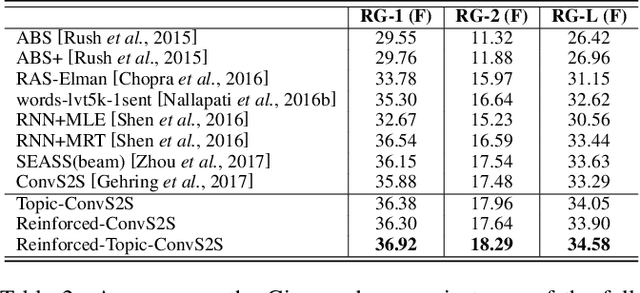

In this paper, we propose a deep learning approach to tackle the automatic summarization tasks by incorporating topic information into the convolutional sequence-to-sequence (ConvS2S) model and using self-critical sequence training (SCST) for optimization. Through jointly attending to topics and word-level alignment, our approach can improve coherence, diversity, and informativeness of generated summaries via a biased probability generation mechanism. On the other hand, reinforcement training, like SCST, directly optimizes the proposed model with respect to the non-differentiable metric ROUGE, which also avoids the exposure bias during inference. We carry out the experimental evaluation with state-of-the-art methods over the Gigaword, DUC-2004, and LCSTS datasets. The empirical results demonstrate the superiority of our proposed method in the abstractive summarization.
SSSC-AM: A Unified Framework for Video Co-Segmentation by Structured Sparse Subspace Clustering with Appearance and Motion Features
Sep 28, 2016


Video co-segmentation refers to the task of jointly segmenting common objects appearing in a given group of videos. In practice, high-dimensional data such as videos can be conceptually thought as being drawn from a union of subspaces corresponding to categories rather than from a smooth manifold. Therefore, segmenting data into respective subspaces --- subspace clustering --- finds widespread applications in computer vision, including co-segmentation. State-of-the-art methods via subspace clustering seek to solve the problem in two steps: First, an affinity matrix is built from data, with appearance features or motion patterns. Second, the data are segmented by applying spectral clustering to the affinity matrix. However, this process is insufficient to obtain an optimal solution since it does not take into account the {\em interdependence} of the affinity matrix with the segmentation. In this work, we present a novel unified video co-segmentation framework inspired by the recent Structured Sparse Subspace Clustering ($\mathrm{S^{3}C}$) based on the {\em self-expressiveness} model. Our method yields more consistent segmentation results. In order to improve the detectability of motion features with missing trajectories due to occlusion or tracked points moving out of frames, we add an extra-dimensional signature to the motion trajectories. Moreover, we reformulate the $\mathrm{S^{3}C}$ algorithm by adding the affine subspace constraint in order to make it more suitable to segment rigid motions lying in affine subspaces of dimension at most $3$. Our experiments on MOViCS dataset show that our framework achieves the highest overall performance among baseline algorithms and demonstrate its robustness to heavy noise.