 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemRNA2vec: mRNA Embedding with Language Model in the 5'UTR-CDS for mRNA Design
Aug 16, 2024Messenger RNA (mRNA)-based vaccines are accelerating the discovery of new drugs and revolutionizing the pharmaceutical industry. However, selecting particular mRNA sequences for vaccines and therapeutics from extensive mRNA libraries is costly. Effective mRNA therapeutics require carefully designed sequences with optimized expression levels and stability. This paper proposes a novel contextual language model (LM)-based embedding method: mRNA2vec. In contrast to existing mRNA embedding approaches, our method is based on the self-supervised teacher-student learning framework of data2vec. We jointly use the 5' untranslated region (UTR) and coding sequence (CDS) region as the input sequences. We adapt our LM-based approach specifically to mRNA by 1) considering the importance of location on the mRNA sequence with probabilistic masking, 2) using Minimum Free Energy (MFE) prediction and Secondary Structure (SS) classification as additional pretext tasks. mRNA2vec demonstrates significant improvements in translation efficiency (TE) and expression level (EL) prediction tasks in UTR compared to SOTA methods such as UTR-LM. It also gives a competitive performance in mRNA stability and protein production level tasks in CDS such as CodonBERT.
Out-of-Distribution Detection using Maximum Entropy Coding
Apr 25, 2024Given a default distribution $P$ and a set of test data $x^M=\{x_1,x_2,\ldots,x_M\}$ this paper seeks to answer the question if it was likely that $x^M$ was generated by $P$. For discrete distributions, the definitive answer is in principle given by Kolmogorov-Martin-L\"{o}f randomness. In this paper we seek to generalize this to continuous distributions. We consider a set of statistics $T_1(x^M),T_2(x^M),\ldots$. To each statistic we associate its maximum entropy distribution and with this a universal source coder. The maximum entropy distributions are subsequently combined to give a total codelength, which is compared with $-\log P(x^M)$. We show that this approach satisfied a number of theoretical properties. For real world data $P$ usually is unknown. We transform data into a standard distribution in the latent space using a bidirectional generate network and use maximum entropy coding there. We compare the resulting method to other methods that also used generative neural networks to detect anomalies. In most cases, our results show better performance.
Investigating the Effect of Hard Negative Sample Distribution on Contrastive Knowledge Graph Embedding
May 17, 2023The success of the knowledge graph completion task heavily depends on the quality of the knowledge graph embeddings (KGEs), which relies on self-supervised learning and augmenting the dataset with negative triples. There is a gap in literature between the theoretical analysis of negative samples on contrastive loss and heuristic generation of quality (i.e., hard) negative triples. In this paper, we modify the InfoNCE loss to explicitly account for the negative sample distribution. We show minimizing InfoNCE loss with hard negatives maximizes the KL-divergence between the given and negative triple embedding. However, we also show that hard negatives can lead to false negatives (i.e., accidentally factual triples) and reduce downstream task performance. To address this issue, we propose a novel negative sample distribution that uses the graph structure of the knowledge graph to remove the false negative triples. We call our algorithm Hardness and Structure-aware (\textbf{HaSa}) contrastive KGE. Experiments show that our method outperforms state-of-the-art KGE methods in several metrics for WN18RR and FB15k-237 datasets.
Out-of-Distribution Detection using BiGAN and MDL
Jun 03, 2022



We consider the following problem: we have a large dataset of normal data available. We are now given a new, possibly quite small, set of data, and we are to decide if these are normal data, or if they are indicating a new phenomenon. This is a novelty detection or out-of-distribution detection problem. An example is in medicine, where the normal data is for people with no known disease, and the new dataset people with symptoms. Other examples could be in security. We solve this problem by training a bidirectional generative adversarial network (BiGAN) on the normal data and using a Gaussian graphical model to model the output. We then use universal source coding, or minimum description length (MDL) on the output to decide if it is a new distribution, in an implementation of Kolmogorov and Martin-L\"{o}f randomness. We apply the methodology to both MNIST data and a real-world electrocardiogram (ECG) dataset of healthy and patients with Kawasaki disease, and show better performance in terms of the ROC curve than similar methods.
How News Evolves? Modeling News Text and Coverage using Graphs and Hawkes Process
Nov 18, 2021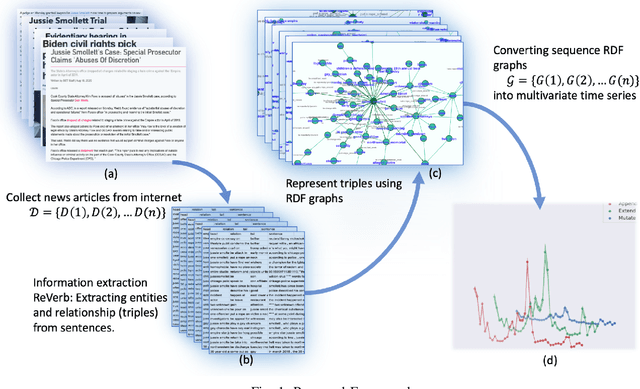
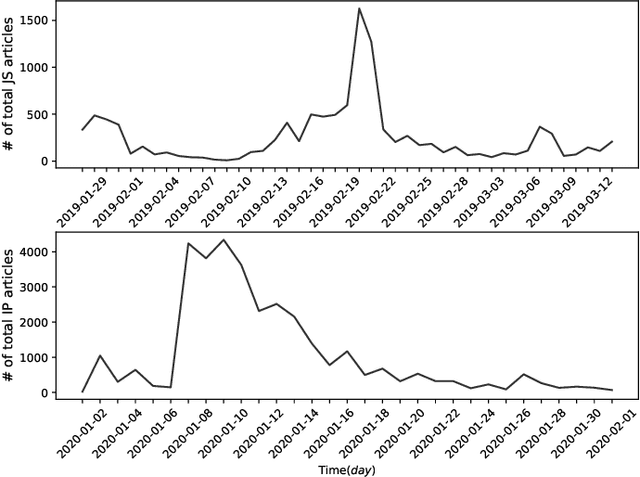


Monitoring news content automatically is an important problem. The news content, unlike traditional text, has a temporal component. However, few works have explored the combination of natural language processing and dynamic system models. One reason is that it is challenging to mathematically model the nuances of natural language. In this paper, we discuss how we built a novel dataset of news articles collected over time. Then, we present a method of converting news text collected over time to a sequence of directed multi-graphs, which represent semantic triples (Subject ! Predicate ! Object). We model the dynamics of specific topological changes from these graphs using discrete-time Hawkes processes. With our real-world data, we show that analyzing the structures of the graphs and the discrete-time Hawkes process model can yield insights on how the news events were covered and how to predict how it may be covered in the future.
Graph Coding for Model Selection and Anomaly Detection in Gaussian Graphical Models
Feb 04, 2021



A classic application of description length is for model selection with the minimum description length (MDL) principle. The focus of this paper is to extend description length for data analysis beyond simple model selection and sequences of scalars. More specifically, we extend the description length for data analysis in Gaussian graphical models. These are powerful tools to model interactions among variables in a sequence of i.i.d Gaussian data in the form of a graph. Our method uses universal graph coding methods to accurately account for model complexity, and therefore provide a more rigorous approach for graph model selection. The developed method is tested with synthetic and electrocardiogram (ECG) data to find the graph model and anomaly in Gaussian graphical models. The experiments show that our method gives better performance compared to commonly used methods.
Differential Description Length for Hyperparameter Selection in Machine Learning
Feb 13, 2019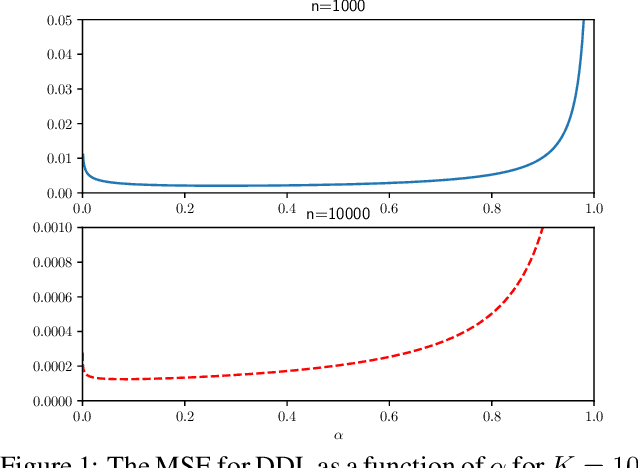
This paper introduces a new method for model selection and more generally hyperparameter selection in machine learning. The paper first proves a relationship between generalization error and a difference of description lengths of the training data; we call this difference differential description length (DDL). This allows prediction of generalization error from the training data \emph{alone} by performing encoding of the training data. This can now be used for model selection by choosing the model that has the smallest predicted generalization error. We show how this encoding can be done for linear regression and neural networks. We provide experiments showing that this leads to smaller generalization error than cross-validation and traditional MDL and Bayes methods.