 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection using Maximum Entropy Coding
Apr 25, 2024Given a default distribution $P$ and a set of test data $x^M=\{x_1,x_2,\ldots,x_M\}$ this paper seeks to answer the question if it was likely that $x^M$ was generated by $P$. For discrete distributions, the definitive answer is in principle given by Kolmogorov-Martin-L\"{o}f randomness. In this paper we seek to generalize this to continuous distributions. We consider a set of statistics $T_1(x^M),T_2(x^M),\ldots$. To each statistic we associate its maximum entropy distribution and with this a universal source coder. The maximum entropy distributions are subsequently combined to give a total codelength, which is compared with $-\log P(x^M)$. We show that this approach satisfied a number of theoretical properties. For real world data $P$ usually is unknown. We transform data into a standard distribution in the latent space using a bidirectional generate network and use maximum entropy coding there. We compare the resulting method to other methods that also used generative neural networks to detect anomalies. In most cases, our results show better performance.
Out-of-Distribution Detection using BiGAN and MDL
Jun 03, 2022



We consider the following problem: we have a large dataset of normal data available. We are now given a new, possibly quite small, set of data, and we are to decide if these are normal data, or if they are indicating a new phenomenon. This is a novelty detection or out-of-distribution detection problem. An example is in medicine, where the normal data is for people with no known disease, and the new dataset people with symptoms. Other examples could be in security. We solve this problem by training a bidirectional generative adversarial network (BiGAN) on the normal data and using a Gaussian graphical model to model the output. We then use universal source coding, or minimum description length (MDL) on the output to decide if it is a new distribution, in an implementation of Kolmogorov and Martin-L\"{o}f randomness. We apply the methodology to both MNIST data and a real-world electrocardiogram (ECG) dataset of healthy and patients with Kawasaki disease, and show better performance in terms of the ROC curve than similar methods.
Graph Coding for Model Selection and Anomaly Detection in Gaussian Graphical Models
Feb 04, 2021



A classic application of description length is for model selection with the minimum description length (MDL) principle. The focus of this paper is to extend description length for data analysis beyond simple model selection and sequences of scalars. More specifically, we extend the description length for data analysis in Gaussian graphical models. These are powerful tools to model interactions among variables in a sequence of i.i.d Gaussian data in the form of a graph. Our method uses universal graph coding methods to accurately account for model complexity, and therefore provide a more rigorous approach for graph model selection. The developed method is tested with synthetic and electrocardiogram (ECG) data to find the graph model and anomaly in Gaussian graphical models. The experiments show that our method gives better performance compared to commonly used methods.
Differential Description Length for Hyperparameter Selection in Machine Learning
Feb 13, 2019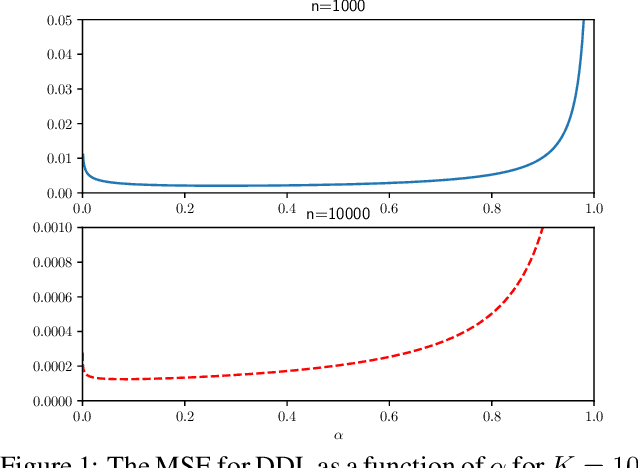
This paper introduces a new method for model selection and more generally hyperparameter selection in machine learning. The paper first proves a relationship between generalization error and a difference of description lengths of the training data; we call this difference differential description length (DDL). This allows prediction of generalization error from the training data \emph{alone} by performing encoding of the training data. This can now be used for model selection by choosing the model that has the smallest predicted generalization error. We show how this encoding can be done for linear regression and neural networks. We provide experiments showing that this leads to smaller generalization error than cross-validation and traditional MDL and Bayes methods.