 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesiDPT: siRNA Efficacy Prediction via Debiased Preference-Pair Transformer
Sep 19, 2025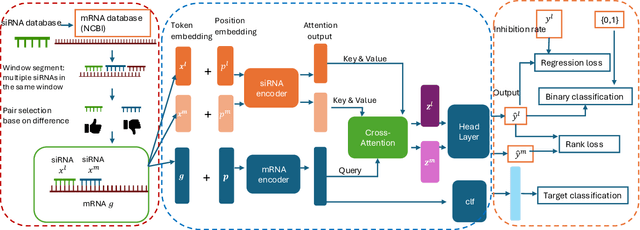
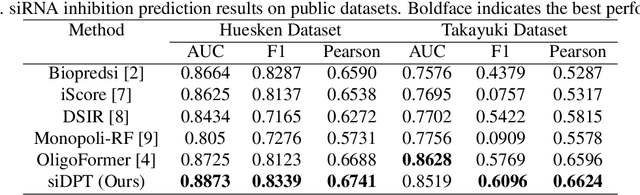
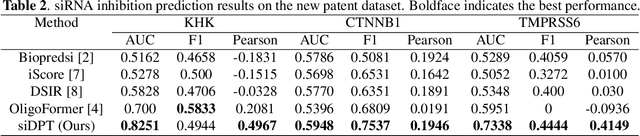
Small interfering RNA (siRNA) is a short double-stranded RNA molecule (about 21-23 nucleotides) with the potential to cure diseases by silencing the function of target genes. Due to its well-understood mechanism, many siRNA-based drugs have been evaluated in clinical trials. However, selecting effective binding regions and designing siRNA sequences requires extensive experimentation, making the process costly. As genomic resources and publicly available siRNA datasets continue to grow, data-driven models can be leveraged to better understand siRNA-mRNA interactions. To fully exploit such data, curating high-quality siRNA datasets is essential to minimize experimental errors and noise. We propose siDPT: siRNA efficacy Prediction via Debiased Preference-Pair Transformer, a framework that constructs a preference-pair dataset and designs an siRNA-mRNA interactive transformer with debiased ranking objectives to improve siRNA inhibition prediction and generalization. We evaluate our approach using two public datasets and one newly collected patent dataset. Our model demonstrates substantial improvement in Pearson correlation and strong performance across other metrics.
mRNA2vec: mRNA Embedding with Language Model in the 5'UTR-CDS for mRNA Design
Aug 16, 2024Messenger RNA (mRNA)-based vaccines are accelerating the discovery of new drugs and revolutionizing the pharmaceutical industry. However, selecting particular mRNA sequences for vaccines and therapeutics from extensive mRNA libraries is costly. Effective mRNA therapeutics require carefully designed sequences with optimized expression levels and stability. This paper proposes a novel contextual language model (LM)-based embedding method: mRNA2vec. In contrast to existing mRNA embedding approaches, our method is based on the self-supervised teacher-student learning framework of data2vec. We jointly use the 5' untranslated region (UTR) and coding sequence (CDS) region as the input sequences. We adapt our LM-based approach specifically to mRNA by 1) considering the importance of location on the mRNA sequence with probabilistic masking, 2) using Minimum Free Energy (MFE) prediction and Secondary Structure (SS) classification as additional pretext tasks. mRNA2vec demonstrates significant improvements in translation efficiency (TE) and expression level (EL) prediction tasks in UTR compared to SOTA methods such as UTR-LM. It also gives a competitive performance in mRNA stability and protein production level tasks in CDS such as CodonBERT.
Investigating the Effect of Hard Negative Sample Distribution on Contrastive Knowledge Graph Embedding
May 17, 2023The success of the knowledge graph completion task heavily depends on the quality of the knowledge graph embeddings (KGEs), which relies on self-supervised learning and augmenting the dataset with negative triples. There is a gap in literature between the theoretical analysis of negative samples on contrastive loss and heuristic generation of quality (i.e., hard) negative triples. In this paper, we modify the InfoNCE loss to explicitly account for the negative sample distribution. We show minimizing InfoNCE loss with hard negatives maximizes the KL-divergence between the given and negative triple embedding. However, we also show that hard negatives can lead to false negatives (i.e., accidentally factual triples) and reduce downstream task performance. To address this issue, we propose a novel negative sample distribution that uses the graph structure of the knowledge graph to remove the false negative triples. We call our algorithm Hardness and Structure-aware (\textbf{HaSa}) contrastive KGE. Experiments show that our method outperforms state-of-the-art KGE methods in several metrics for WN18RR and FB15k-237 datasets.
How News Evolves? Modeling News Text and Coverage using Graphs and Hawkes Process
Nov 18, 2021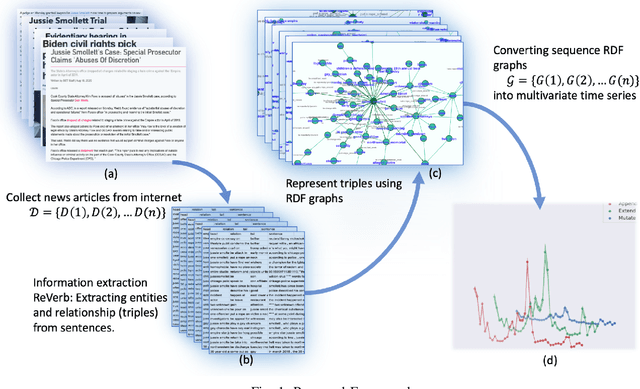
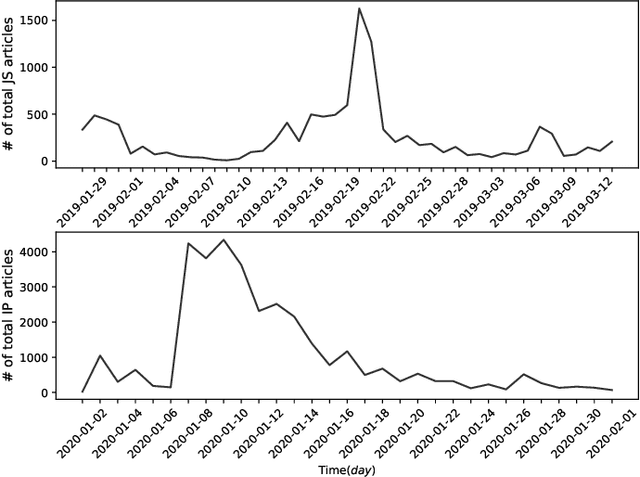


Monitoring news content automatically is an important problem. The news content, unlike traditional text, has a temporal component. However, few works have explored the combination of natural language processing and dynamic system models. One reason is that it is challenging to mathematically model the nuances of natural language. In this paper, we discuss how we built a novel dataset of news articles collected over time. Then, we present a method of converting news text collected over time to a sequence of directed multi-graphs, which represent semantic triples (Subject ! Predicate ! Object). We model the dynamics of specific topological changes from these graphs using discrete-time Hawkes processes. With our real-world data, we show that analyzing the structures of the graphs and the discrete-time Hawkes process model can yield insights on how the news events were covered and how to predict how it may be covered in the future.