 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuSemShift: a dataset of historical lexical semantic change in Russian
Oct 13, 2020


We present RuSemShift, a large-scale manually annotated test set for the task of semantic change modeling in Russian for two long-term time period pairs: from the pre-Soviet through the Soviet times and from the Soviet through the post-Soviet times. Target words were annotated by multiple crowd-source workers. The annotation process was organized following the DURel framework and was based on sentence contexts extracted from the Russian National Corpus. Additionally, we report the performance of several distributional approaches on RuSemShift, achieving promising results, which at the same time leave room for other researchers to improve.
ELMo and BERT in semantic change detection for Russian
Oct 07, 2020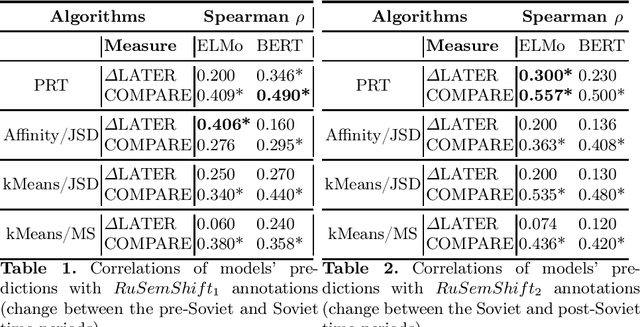
We study the effectiveness of contextualized embeddings for the task of diachronic semantic change detection for Russian language data. Evaluation test sets consist of Russian nouns and adjectives annotated based on their occurrences in texts created in pre-Soviet, Soviet and post-Soviet time periods. ELMo and BERT architectures are compared on the task of ranking Russian words according to the degree of their semantic change over time. We use several methods for aggregation of contextualized embeddings from these architectures and evaluate their performance. Finally, we compare unsupervised and supervised techniques in this task.
Tracing cultural diachronic semantic shifts in Russian using word embeddings: test sets and baselines
May 16, 2019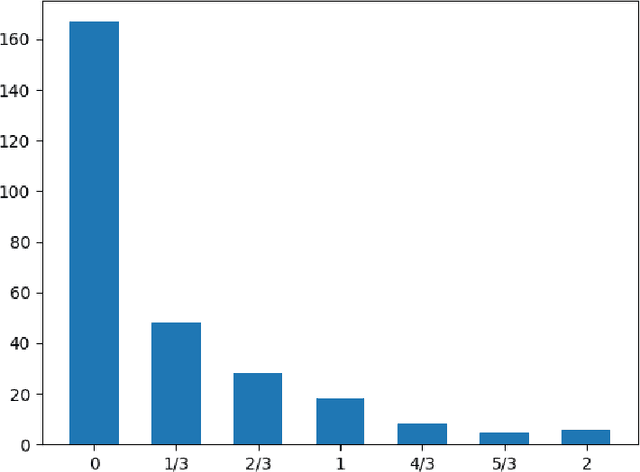

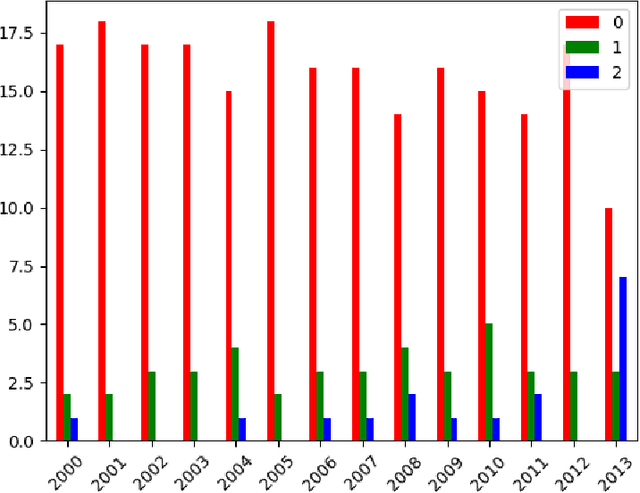
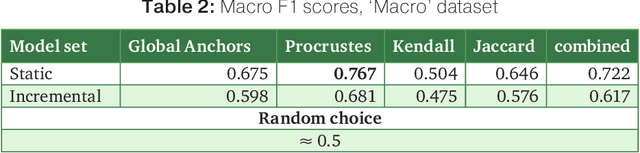
The paper introduces manually annotated test sets for the task of tracing diachronic (temporal) semantic shifts in Russian. The two test sets are complementary in that the first one covers comparatively strong semantic changes occurring to nouns and adjectives from pre-Soviet to Soviet times, while the second one covers comparatively subtle socially and culturally determined shifts occurring in years from 2000 to 2014. Additionally, the second test set offers more granular classification of shifts degree, but is limited to only adjectives. The introduction of the test sets allowed us to evaluate several well-established algorithms of semantic shifts detection (posing this as a classification problem), most of which have never been tested on Russian material. All of these algorithms use distributional word embedding models trained on the corresponding in-domain corpora. The resulting scores provide solid comparison baselines for future studies tackling similar tasks. We publish the datasets, code and the trained models in order to facilitate further research in automatically detecting temporal semantic shifts for Russian words, with time periods of different granularities.