 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure
Jan 02, 2021

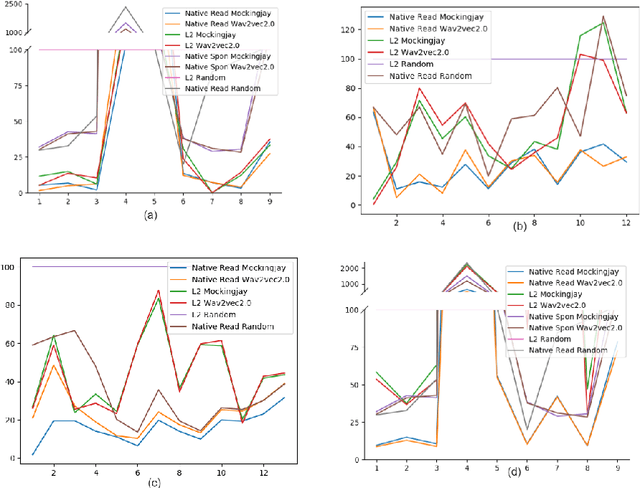

In recent times, BERT based transformer models have become an inseparable part of the 'tech stack' of text processing models. Similar progress is being observed in the speech domain with a multitude of models observing state-of-the-art results by using audio transformer models to encode speech. This begs the question of what are these audio transformer models learning. Moreover, although the standard methodology is to choose the last layer embedding for any downstream task, but is it the optimal choice? We try to answer these questions for the two recent audio transformer models, Mockingjay and wave2vec2.0. We compare them on a comprehensive set of language delivery and structure features including audio, fluency and pronunciation features. Additionally, we probe the audio models' understanding of textual surface, syntax, and semantic features and compare them to BERT. We do this over exhaustive settings for native, non-native, synthetic, read and spontaneous speech datasets
CinC-GAN for Effective F0 prediction for Whisper-to-Normal Speech Conversion
Aug 18, 2020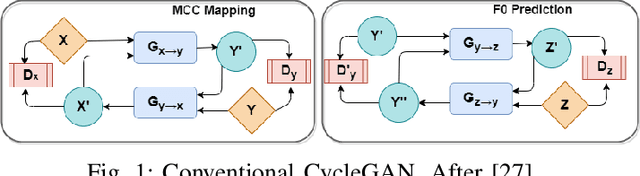
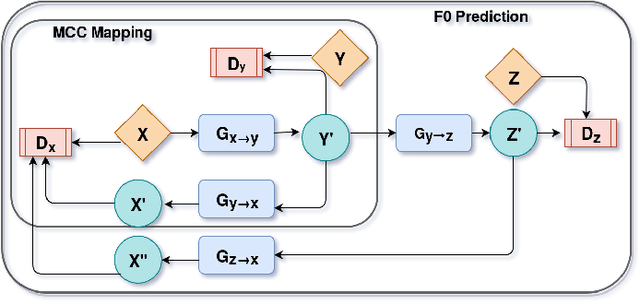
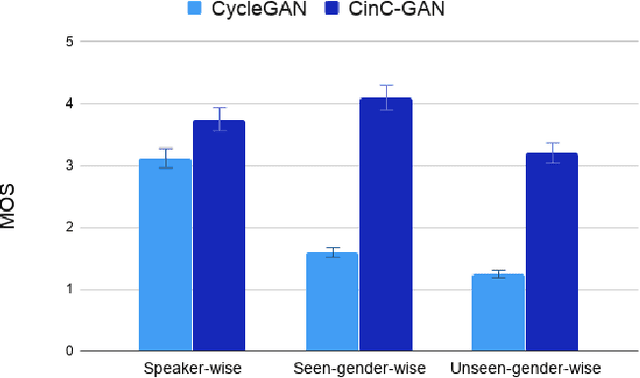
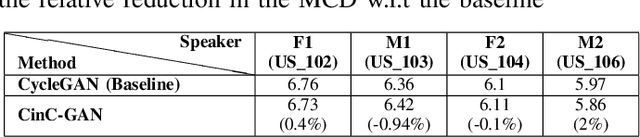
Recently, Generative Adversarial Networks (GAN)-based methods have shown remarkable performance for the Voice Conversion and WHiSPer-to-normal SPeeCH (WHSP2SPCH) conversion. One of the key challenges in WHSP2SPCH conversion is the prediction of fundamental frequency (F0). Recently, authors have proposed state-of-the-art method Cycle-Consistent Generative Adversarial Networks (CycleGAN) for WHSP2SPCH conversion. The CycleGAN-based method uses two different models, one for Mel Cepstral Coefficients (MCC) mapping, and another for F0 prediction, where F0 is highly dependent on the pre-trained model of MCC mapping. This leads to additional non-linear noise in predicted F0. To suppress this noise, we propose Cycle-in-Cycle GAN (i.e., CinC-GAN). It is specially designed to increase the effectiveness in F0 prediction without losing the accuracy of MCC mapping. We evaluated the proposed method on a non-parallel setting and analyzed on speaker-specific, and gender-specific tasks. The objective and subjective tests show that CinC-GAN significantly outperforms the CycleGAN. In addition, we analyze the CycleGAN and CinC-GAN for unseen speakers and the results show the clear superiority of CinC-GAN.