 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktracking Spatial Pyramid Pooling (SPP)-based Image Classifier for Weakly Supervised Top-down Salient Object Detection
Aug 14, 2018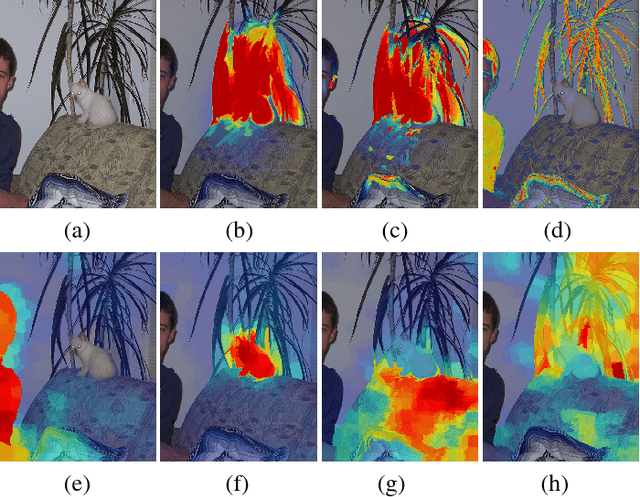
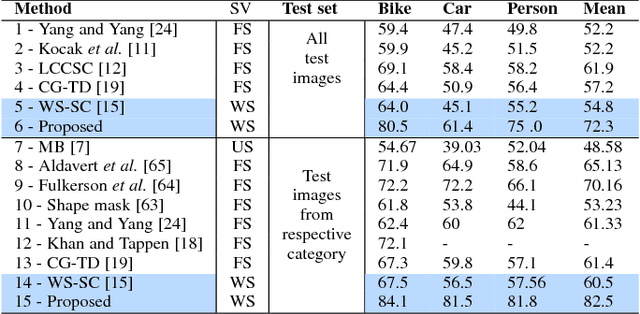


Top-down saliency models produce a probability map that peaks at target locations specified by a task/goal such as object detection. They are usually trained in a fully supervised setting involving pixel-level annotations of objects. We propose a weakly supervised top-down saliency framework using only binary labels that indicate the presence/absence of an object in an image. First, the probabilistic contribution of each image region to the confidence of a CNN-based image classifier is computed through a backtracking strategy to produce top-down saliency. From a set of saliency maps of an image produced by fast bottom-up saliency approaches, we select the best saliency map suitable for the top-down task. The selected bottom-up saliency map is combined with the top-down saliency map. Features having high combined saliency are used to train a linear SVM classifier to estimate feature saliency. This is integrated with combined saliency and further refined through a multi-scale superpixel-averaging of saliency map. We evaluate the performance of the proposed weakly supervised topdown saliency and achieve comparable performance with fully supervised approaches. Experiments are carried out on seven challenging datasets and quantitative results are compared with 40 closely related approaches across 4 different applications.
* 14 pages, 7 figures
Person re-identification with fusion of hand-crafted and deep pose-based body region features
Mar 27, 2018

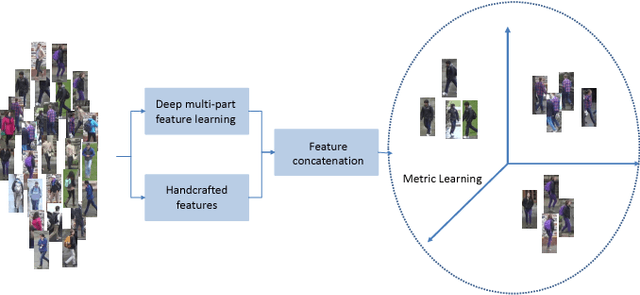
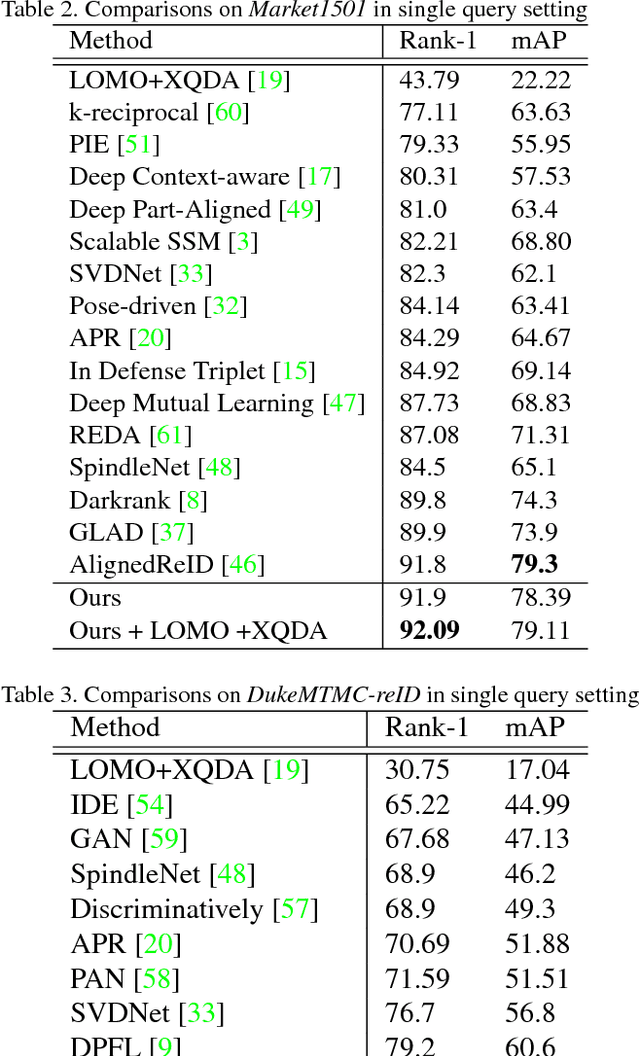
Person re-identification (re-ID) aims to accurately re- trieve a person from a large-scale database of images cap- tured across multiple cameras. Existing works learn deep representations using a large training subset of unique per- sons. However, identifying unseen persons is critical for a good re-ID algorithm. Moreover, the misalignment be- tween person crops to detection errors or pose variations leads to poor feature matching. In this work, we present a fusion of handcrafted features and deep feature representa- tion learned using multiple body parts to complement the global body features that achieves high performance on un- seen test images. Pose information is used to detect body regions that are passed through Convolutional Neural Net- works (CNN) to guide feature learning. Finally, a metric learning step enables robust distance matching on a dis- criminative subspace. Experimental results on 4 popular re-ID benchmark datasets namely VIPer, DukeMTMC-reID, Market-1501 and CUHK03 show that the proposed method achieves state-of-the-art performance in image-based per- son re-identification.
L1-regularized Reconstruction Error as Alpha Matte
Feb 09, 2017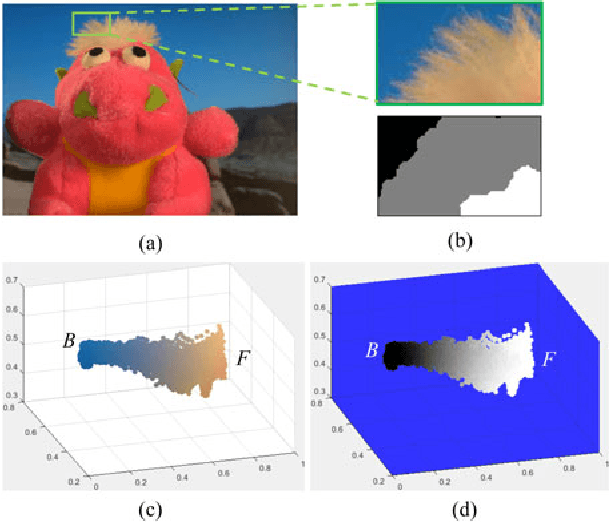


Sampling-based alpha matting methods have traditionally followed the compositing equation to estimate the alpha value at a pixel from a pair of foreground (F) and background (B) samples. The (F,B) pair that produces the least reconstruction error is selected, followed by alpha estimation. The significance of that residual error has been left unexamined. In this letter, we propose a video matting algorithm that uses L1-regularized reconstruction error of F and B samples as a measure of the alpha matte. A multi-frame non-local means framework using coherency sensitive hashing is utilized to ensure temporal coherency in the video mattes. Qualitative and quantitative evaluations on a dataset exclusively for video matting demonstrate the effectiveness of the proposed matting algorithm.
A Classifier-guided Approach for Top-down Salient Object Detection
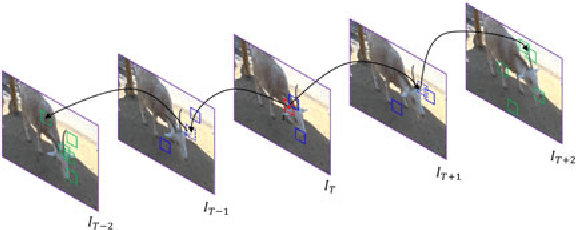
Apr 22, 2016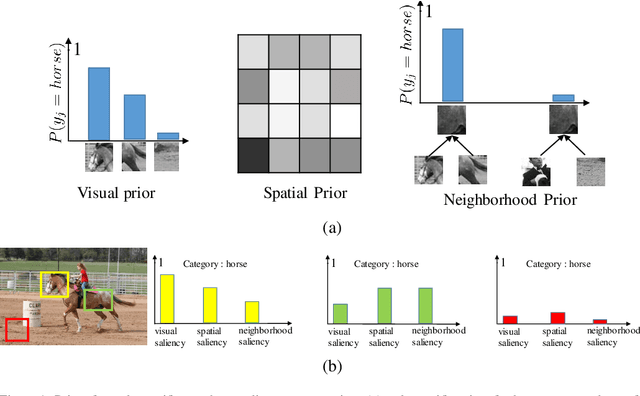
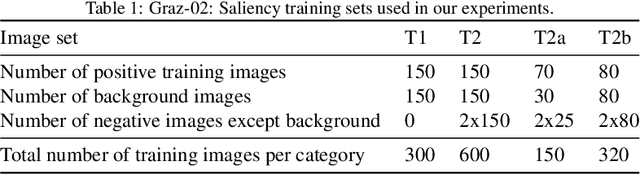
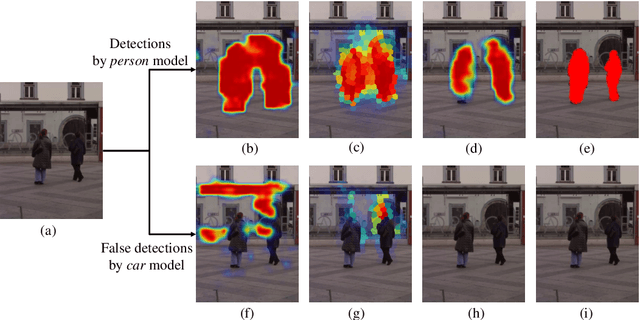
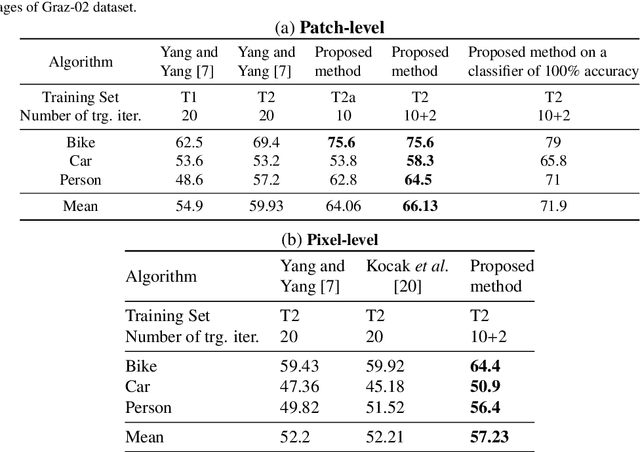
We propose a framework for top-down salient object detection that incorporates a tightly coupled image classification module. The classifier is trained on novel category-aware sparse codes computed on object dictionaries used for saliency modeling. A misclassification indicates that the corresponding saliency model is inaccurate. Hence, the classifier selects images for which the saliency models need to be updated. The category-aware sparse coding produces better image classification accuracy as compared to conventional sparse coding with a reduced computational complexity. A saliency-weighted max-pooling is proposed to improve image classification, which is further used to refine the saliency maps. Experimental results on Graz-02 and PASCAL VOC-07 datasets demonstrate the effectiveness of salient object detection. Although the role of the classifier is to support salient object detection, we evaluate its performance in image classification and also illustrate the utility of thresholded saliency maps for image segmentation.
Sparse Coding for Alpha Matting
Apr 11, 2016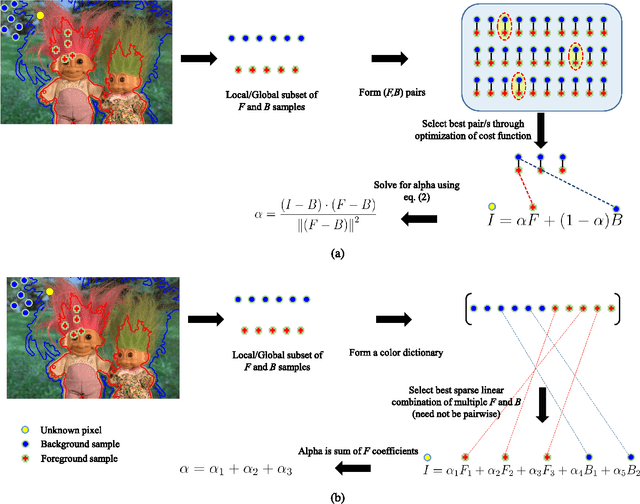



Existing color sampling based alpha matting methods use the compositing equation to estimate alpha at a pixel from pairs of foreground (F) and background (B) samples. The quality of the matte depends on the selected (F,B) pairs. In this paper, the matting problem is reinterpreted as a sparse coding of pixel features, wherein the sum of the codes gives the estimate of the alpha matte from a set of unpaired F and B samples. A non-parametric probabilistic segmentation provides a certainty measure on the pixel belonging to foreground or background, based on which a dictionary is formed for use in sparse coding. By removing the restriction to conform to (F,B) pairs, this method allows for better alpha estimation from multiple F and B samples. The same framework is extended to videos, where the requirement of temporal coherence is handled effectively. Here, the dictionary is formed by samples from multiple frames. A multi-frame graph model, as opposed to a single image as for image matting, is proposed that can be solved efficiently in closed form. Quantitative and qualitative evaluations on a benchmark dataset are provided to show that the proposed method outperforms current state-of-the-art in image and video matting.