 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktracking Spatial Pyramid Pooling (SPP)-based Image Classifier for Weakly Supervised Top-down Salient Object Detection
Paper and Code
Aug 14, 2018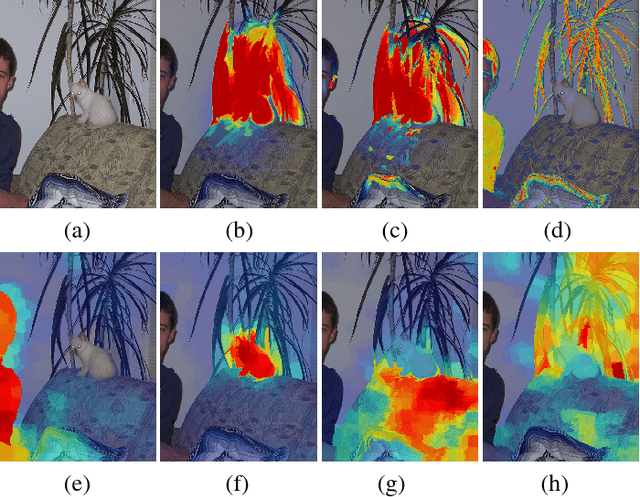
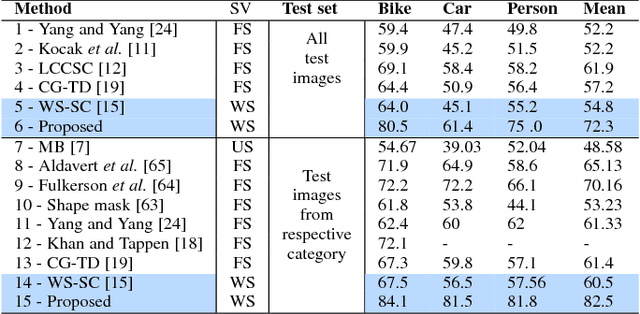


Top-down saliency models produce a probability map that peaks at target locations specified by a task/goal such as object detection. They are usually trained in a fully supervised setting involving pixel-level annotations of objects. We propose a weakly supervised top-down saliency framework using only binary labels that indicate the presence/absence of an object in an image. First, the probabilistic contribution of each image region to the confidence of a CNN-based image classifier is computed through a backtracking strategy to produce top-down saliency. From a set of saliency maps of an image produced by fast bottom-up saliency approaches, we select the best saliency map suitable for the top-down task. The selected bottom-up saliency map is combined with the top-down saliency map. Features having high combined saliency are used to train a linear SVM classifier to estimate feature saliency. This is integrated with combined saliency and further refined through a multi-scale superpixel-averaging of saliency map. We evaluate the performance of the proposed weakly supervised topdown saliency and achieve comparable performance with fully supervised approaches. Experiments are carried out on seven challenging datasets and quantitative results are compared with 40 closely related approaches across 4 different applications.